Herramientas de usuario
Barra lateral
clase:iabd:pia:2eval:tema07-apendices-metricas
¡Esta es una revisión vieja del documento!
7. Entrenamiento de redes neuronales e) Apéndices Métricas
En este apartado vamos a ampliar las métricas que podemos usar con la clasificación binaria las cuales ya vimos en 7. Entrenamiento de redes neuronales c) Métricas.
Para ampliar nos vamos a basar en este diagrama (que se puede ver en Matriz de confusión en Wikipedia)
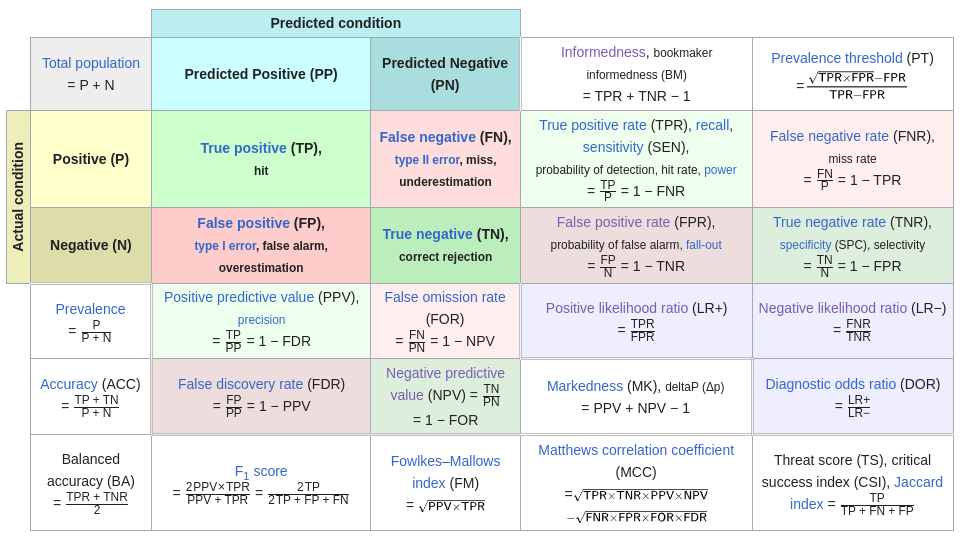
Las métricas que ya las hemos explicado en el tema de métricas son:
- Métricas básicas (Sensibilidad, Especificidad, FNR y FPR)
- Métricas derivadas según el teorema de bayes (PPV,NPV, FDR y FOR)
Las métricas que ahora vamos a ver son métricas que hacen la media entre alguna de las dos métricas que acabamos de indicar.
Para organizar las métricas según 2 criterios:
- Según que métricas juntan
- Métricas básicas (Sensibilidad, Especificidad, FNR y FPR)
- Métricas derivadas (PPV,NPV, FDR y FOR)
- Métricas mixtas, que usa una básica y otra derivada.
- Según la fórmula que usan:
- Media aritmética
- Media armónica
- Media geométrica
- Suma-1
- Ratio
Juntado dos Métricas Básicas
Las 4 métricas básicas son Sensibilidad, Especificidad, FPR y FNR. Según eso existen las siguientes métricas:
- La siguiente tabla son métricas que existen (Tienen nombre)
| Fórmula que usan | |||||
|---|---|---|---|---|---|
| Métricas básicas que usan | Media aritmética | Media armónica | Media geométrica | Suma-1 | Ratio |
| Sensibilidad (TPR) y Especificidad (TNR) | $Balanced \; Accuracy=\frac{TPR+TNR}{2}$ | $Informedness=TPR+TNR-1$ | |||
| Sensibilidad (TPR) y FPR | $Positive \; likelihood \; ratio=\frac{TPR}{FPR}$ | ||||
| Especificidad (TNR) y FNR | $Negative \; likelihood \; ratio=\frac{FNR}{TNR}$ | ||||
| FPR y FNR | |||||
- La siguiente tabla son métricas que no existen (No tienen nombre)
| Fórmula que usan | |||||
|---|---|---|---|---|---|
| Métricas básicas que usan | Media aritmética | Media armónica | Media geométrica | Suma-1 | Ratio |
| Sensibilidad (TPR) y Especificidad (TNR) | $\frac{1}{\frac{1}{TPR}+\frac{1}{TNR}}$ | $\sqrt{TPR*TNR}$ | $\frac{TPR}{TNR}$ y $\frac{TNR}{TPR}$ | ||
| Sensibilidad (TPR) y FPR | $\frac{TPR+FPR}{2}$ | $\frac{1}{\frac{1}{TPR}+\frac{1}{FPR}}$ | $\sqrt{TPR*FPR}$ | $TPR+FPR-1$ | $\frac{FPR}{TPR}$ |
| Especificidad (TNR) y FNR | $\frac{TNR+FNR}{2}$ | $\frac{1}{\frac{1}{TNR}+\frac{1}{FNR}}$ | $\sqrt{TNR*FNR}$ | $TNR+FNR-1$ | $\frac{TNR}{FNR}$ |
| FPR y FNR | $\frac{FPR+FNR}{2}$ | $\frac{1}{\frac{1}{FPR}+\frac{1}{FNR}}$ | $\sqrt{FPR*FNR}$ | $FPR+FNR-1$ | $\frac{FNR}{FPR}$ y $\frac{FPR}{FNR}$ |
No tiene sentido que se junten las métricas de TPR y FNR o las métricas de FPR y TNR ya que entre ellas son complementarias. Es decir que TPR+FNR=1 y que FPR+TNR=1
Juntado dos Métricas derivadas
Las 4 métricas derivadas son PPV, NPV, FDR y FOR.
- La siguiente tabla son métricas que existen (Tienen nombre)
| Fórmula que usan | |||||
|---|---|---|---|---|---|
| Métricas básicas que usan | Media aritmética | Media armónica | Media geométrica | Suma-1 | Ratio |
| PPV y NPV | $Markdness=PPV+NPV-1$ | ||||
| PPV y FOR | |||||
| NPV y FDR | |||||
| FDR y FOR | |||||
- La siguiente tabla son métricas que no existen (No tienen nombre)
| Fórmula que usan | |||||
|---|---|---|---|---|---|
| Métricas básicas que usan | Media aritmética | Media armónica | Media geométrica | Suma-1 | Ratio |
| PPV y NPV | $\frac{PPV+NPV}{2}$ | $\frac{1}{\frac{1}{PPV}+\frac{1}{NPV}}$ | $\sqrt{PPV*NPV}$ | $\frac{PPV}{NPV}$ y $\frac{NPV}{PPV}$ | |
| PPV y FOR | $\frac{PPV+FOR}{2}$ | $\frac{1}{\frac{1}{PPV}+\frac{1}{FOR}}$ | $\sqrt{PPV*FOR}$ | $PPV+FOR-1$ | $\frac{PPV}{FOR}$ y $\frac{FOR}{PPV}$ |
| NPV y FDR | $\frac{NPV+FDR}{2}$ | $\frac{1}{\frac{1}{NPV}+\frac{1}{FDR}}$ | $\sqrt{NPV*FDR}$ | $NPV+FDR-1$ | $\frac{NPV}{FDR}$ y $\frac{FDR}{NPV}$ |
| FDR y FOR | $\frac{FDR+FOR}{2}$ | $\frac{1}{\frac{1}{FDR}+\frac{1}{FOR}}$ | $\sqrt{FDR*FOR}$ | $FDR+FOR-1$ | $\frac{FDR}{FOR}$ y $\frac{FOR}{FDR}$ |
No tiene sentido que se junten las métricas de PPV y FDR o las métricas de NPV y FOR ya que entre ellas son complementarias. Es decir que PPV+FDR=1 y que NPV+FOR=1
Métricas mixtas
Son métricas que juntan una métrica básica con una métrica derivada. Debido a que existen 16 combinaciones no vamos a mostrar todas las que existen, sino solo las que he considerado interesantes.
- La siguiente tabla son métricas que existen (Tienen nombre)
| Fórmula que usan | |||||
|---|---|---|---|---|---|
| Métricas básicas que usan | Media aritmética | Media armónica | Media geométrica | Suma-1 | Ratio |
| PPV y Sensibilidad (TPR) | $F_{1}score=\frac{1}{\frac{1}{PPV}+\frac{1}{TPR}}$ | $Fowlkes-Mallows \; index=\sqrt{PPV*TPR}$ | |||
| NPV y Especificidad (TNR) | |||||
- La siguiente tabla son métricas que no existen (No tienen nombre)
| Fórmula que usan | |||||
|---|---|---|---|---|---|
| Métricas básicas que usan | Media aritmética | Media armónica | Media geométrica | Suma-1 | Ratio |
| PPV y Sensibilidad (TPR) | $\frac{PPV+TPR}{2}$ | $PPV+TPR-1$ | $\frac{PPV}{TPR}$ y $\frac{TPR}{PPV}$ | ||
| NPV y Especificidad (TNR) | $\frac{NPV+TNR}{2}$ | $\frac{1}{\frac{1}{NPV}+\frac{1}{TNR}}$ | $\sqrt{NPV*TNR}$ | $NPV+TNR-1$ | $\frac{NPV}{TNR}$ y $\frac{TNR}{NPV}$ |
Otras métricas
Veamos ahora otras métricas que si que existen pero no encajan en organización que habíamos creado.
Accuracy
Accuracy (Exactitud) mide la proporción de predicciones correctas sobre el total de predicciones realizadas. Por lo que su fórmula es:
$$ Accuracy=\frac{TP+TN}{TP+FN+FP+TN} $$
Debido a que usa los 4 valores vamos a expresar la misma fórmula usando Especificidad, Sensibilidad y Prevalencia. Esto se hace ya que así podremos usar la prevalencia que queramos y no la de nuestros datos.
$$ Accuracy=P(Predicción \; correcta|Predicción \; realizada) $$
Eso se puede expresar como la suma de 2 probabilidades
$$ P(Predicción \; correcta|Predicción \; realizada)=P(Positivo \cap Enfermo) + P(Negativo \cap Sano)= $$
$$ P(Positivo|Enfermo)*P(Enfermo)+P(Negativo|Sano)*P(Sano)=Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia) $$
Vamos a ver que para la prevalencia de los datos, las 2 fórmulas son iguales.
$$ Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia)=\frac{TP}{(TP+FN)}*\frac{(TP+FN)}{TP+FN+FP+TN}+\frac{TN}{(FP+TN)}*\frac{(FP+TN)}{TP+FN+FP+TN}= $$
$$ \frac{TP}{TP+FN+FP+TN}+\frac{TN}{TP+FN+FP+TN}=\frac{TP+TN}{TP+FN+FP+TN}=Accuracy $$
Por lo tanto:
$$ Accuracy=Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia) $$
Accuracy y Balanced Accuracy
Veamos ahora la relación que hay entre Accuracy y Balanced Accuracy.
$$ Balanced \; Accuracy=\frac{Sensibilidad+Especificidad}{2} $$
Pero si calculamos Accuracy suponiendo que la $Prevalencia=0.5$ obtenemos:
$$ Accuracy=Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia)= $$
$$ Sensibilidad*0,5+Especificidad*(1-0,5)=Sensibilidad*0,5+Especificidad*0,5= $$
$$ \frac{Sensibilidad}{2}+\frac{Especificidad}{2}=\frac{Sensibilidad+Especificidad}{2}=Balanced \; Accuracy $$
Indice Jaccard
Este índice es la división entre 2 probabilidades:
$$ Indice \; Jaccard=\frac{P(Positivo \cap Enfermo)}{P(Positivo \cup Enfermo)}=\frac{TP}{TP+FP+FN} $$
Se deduce de la siguiente forma:
$$ \frac{P(Positivo \cap Enfermo)}{P(Positivo \cup Enfermo)}= $$
$$ \frac{P(Positivo|Enfermo)*P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo \cap Enfermo)}=\frac{P(Positivo|Enfermo)*P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo|Enfermo)*P(Enfermo)} $$
Sabiendo que:
$$ \begin{array} \\ P(Enfermo)&=&\frac{TP+FN}{TP+FN+FP+TN} \\ P(Sano)&=&\frac{FP+TN}{TP+FN+FP+TN} \\ P(Positivo)&=&\frac{TP+FP}{TP+FN+FP+TN} \\ P(Negativo)&=&\frac{FN+TN}{TP+FN+FP+TN} \\ P(Positivo|Enfermo)&=&\frac{TP}{TP+FN} \end{array} $$
Entonces:
$$ \frac{P(Positivo|Enfermo)*P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo|Enfermo)*P(Enfermo)}= $$
$$ \left ( \frac{TP}{TP+FN}*\frac{TP+FN}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP}{TP+FN+FP+TN}+\frac{TP+FN}{TP+FN+FP+TN}-\frac{TP}{TP+FN}*\frac{TP+FN}{TP+FN+FP+TN} \right )= $$
$$ \left ( \frac{TP}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP}{TP+FN+FP+TN}+\frac{TP+FN}{TP+FN+FP+TN}-\frac{TP}{TP+FN+FP+TN} \right )= $$
$$ \left ( \frac{TP}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP+TP+FN-TP}{TP+FN+FP+TN} \right )=\left ( \frac{TP}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP+FN}{TP+FN+FP+TN} \right )= $$
$$ \frac{TP}{TP+FP+FN}=Indice \; Jaccard $$
Prevalence threshold
La métrica de Prevalence threshold está explicada en Prevalence threshold (ϕe) and the geometry of screening curves.
Lo único que diremos respecto a la formula es que en el artículo aparece como:
$$ Prevalence \; threshold=\frac{\sqrt{Sensibilidad(1-Especificidad)}+(Especificidad-1)}{Sensibilidad+Especificidad+1} $$ Que jugando un poco con los signos se obtiene la formula equivalente: $$ Prevalence \; threshold=\frac{\sqrt{Sensibilidad*FPR}-FPR}{Sensibilidad-FPR} $$
Matthews correlation coefficient
Es otra métrica pero que tiene en cuenta que los datos no estén balanceados.
El MMC tiene un valor entre -1 a 1. Siendo:
- 1 : El clasificador funciona perfectamente
- 0 : El clasificador acierta aleatoriamente
- -1 : El clasificador acierta peor que aleatoriamente, es decir que clasifica al revés "perfectamente"
$$MCC = \frac{ \mathit{TP} \times \mathit{TN} - \mathit{FP} \times \mathit{FN} } {\sqrt{ (\mathit{TP} + \mathit{FP}) ( \mathit{TP} + \mathit{FN} ) ( \mathit{TN} + \mathit{FP} ) ( \mathit{TN} + \mathit{FN} ) } }$$
Podemos hacer uso de la métrica con la función sklearn.metrics.matthews_corrcoef de sklearn
Ejemplo de uso:
from sklearn.metrics import matthews_corrcoef
y_true = [1,1,1,1,0,0,0,0]
y_pred = [1,1,1,1,0,0,0,0]
print("Valor para una predicción que acierta siempre=",matthews_corrcoef(y_true,y_pred))
y_true = [1,1,1,1,0,0,0,0]
y_pred = [1,1,0,0,1,1,0,0]
print("Valor para una predicción que acierta la mitad=",matthews_corrcoef(y_true,y_pred))
y_true = [1,1,1,1,0,0,0,0]
y_pred = [0,0,0,0,1,1,1,1]
print("Valor para una predicción que nunca acierta=",matthews_corrcoef(y_true,y_pred))
Valor para una predicción que acierta siempre= 1.0 Valor para una predicción que acierta la mitad= 0.0 Valor para una predicción que nunca acierta= -1.0
La métrica también está en tfa.metrics.MatthewsCorrelationCoefficient pero
he visto que no tiene el parámetro
threshold por lo que supongo que solo trabaja con valores de predicción y no de score.
Además en https://stackoverflow.com/questions/56865344/how-do-i-calculate-the-matthews-correlation-coefficient-in-tensorflow se indica que:
Also please note that MCC values printed from Keras during iterations will be incorrect because of the metric calculation per batch size. You can only trust MCC value from calling "evaluate" or "score" after fitting. This is because MCC for the whole sample is not the sum/average of the parts, unlike the other metrics. For example, if your batch size is one, MCC printed will be zero during iterations.
Mas información:
clase/iabd/pia/2eval/tema07-apendices-metricas.1710009342.txt.gz · Última modificación: 2024/03/09 19:35 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
