Herramientas de usuario
Barra lateral
clase:iabd:pia:2eval:tema07-apendices
Tabla de Contenidos
¡Esta es una revisión vieja del documento!
7. Entrenamiento de redes neuronales: Apéndices
Tipos de funciones de coste
MAE
El error absoluto medio o en inglés Mean Absolute Error (MAE) suma el valor absoluto de los errores. Al hacer el valor absoluto de cada error, no se cancelarán si hay errores positivos y negativos.
Su fórmula es:
$$MAE = \frac{1}{N} \sum_{i=1}^{N}|y_{i} - \hat{y_{i}}|$$
Su uso en Keras es:
model.compile(loss="mean_absolute_error") model.compile(loss="mae")
Mas información:
Huber
La función de coste Huber es un compromiso entre MAE y MSE, ese compromiso se define con un parámetro llamado delta $\delta$. La siguiente gráfica compara MAE, MSE y distintos valores de delta.
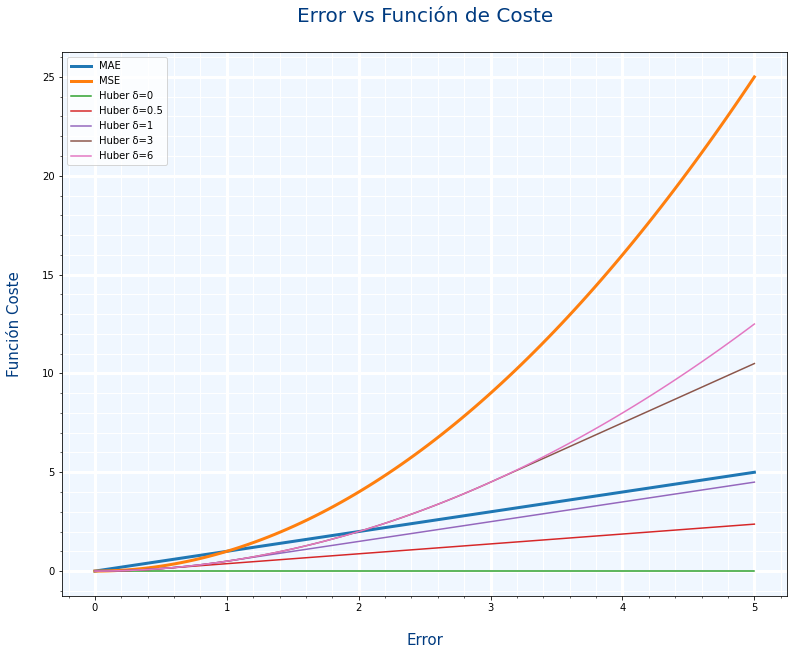
- Si delta tiene en valor cercano a 1, tenderá a parecerse a MAE
- Si delta tiene un valor elevado, tenderá a parecerse a MSE
Como decíamos con MAE y MSE. ¿queremos que los valores extremos se tengan en cuenta. Pues con el parámetro delta podemos hacer un ajuste mas fino
Su uso en Keras es:
model.compile(loss=tf.keras.losses.Huber(delta=3))
Pensando en la gráfica de Huber he pensado si $MAE=|y-\hat{y}|^1 $ y $MSE=|y-\hat{y}|^2$, en vez de usar Huber, ¿No podríamos usar como función de coste algo también intermedio como $MSE=|y-\hat{y}|^{1.5}$
Y he creado una gráfica similar para ver los resultados y no están mal
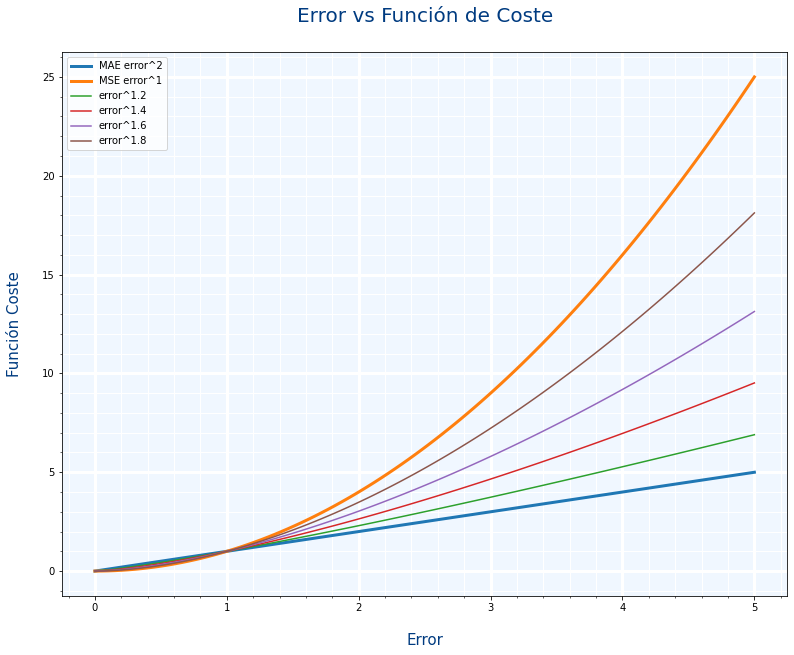
He mirado un poco por internet para ver si alguien los usaba y no he encontrado nada, supongo que será porque hacer el cálculo de una potencia con decimales es bastante costoso en tiempo.
Mas información:
clase/iabd/pia/2eval/tema07-apendices.1640688142.txt.gz · Última modificación: 2021/12/28 11:42 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
