Herramientas de usuario
Barra lateral
clase:iabd:pia:2eval:tema07.metricas_derivadas
Tabla de Contenidos
7. Entrenamiento de redes neuronales d) Métricas derivadas
En este apartado vamos a ampliar las métricas que podemos usar con la clasificación binaria las cuales ya vimos en 7. Entrenamiento de redes neuronales c) Métricas.
Para ampliar nos vamos a basar en este diagrama (que se puede ver en Matriz de confusión en Wikipedia)
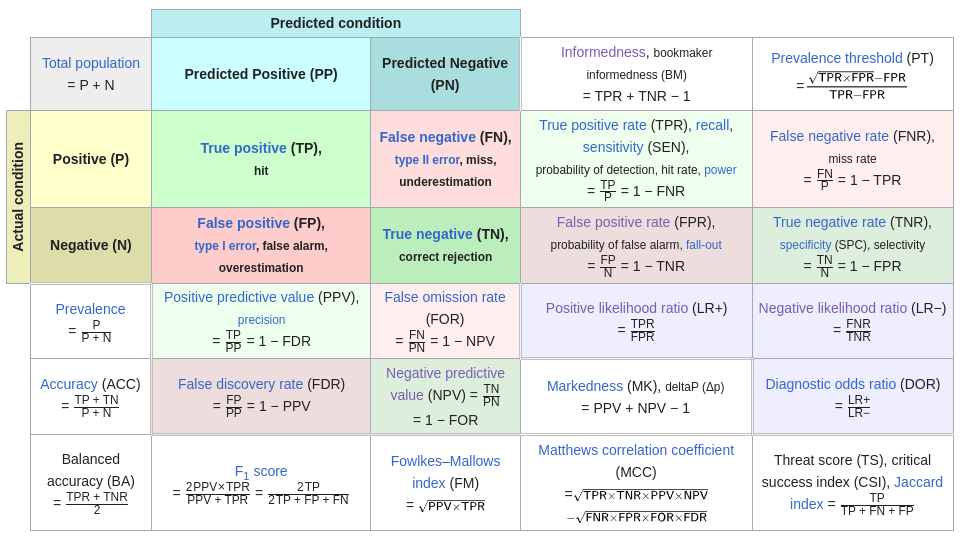
Las métricas que ya las hemos explicado en el tema de métricas son:
- Métricas básicas (Sensibilidad, Especificidad, FNR y FPR)
- Métricas derivadas según el teorema de bayes (PPV,NPV, FDR y FOR)
Las métricas que ahora vamos a ver son métricas que hacen la media entre dos métricas de las que acabamos de indicar.
Para organizar las métricas según 2 criterios:
- Según que métricas juntan
- Métricas básicas (Sensibilidad, Especificidad, FNR y FPR)
- Métricas derivadas (PPV,NPV, FDR y FOR)
- Métricas mixtas, que usa una básica y otra derivada.
Juntado dos Métricas Básicas
Las 4 métricas básicas son Sensibilidad, Especificidad, FPR y FNR. Según eso existen las siguientes métricas:
Accuracy
Accuracy (Exactitud) mide la proporción de predicciones correctas sobre el total de predicciones realizadas. Por lo que su fórmula es:
$$ Accuracy=\frac{TP+TN}{TP+FN+FP+TN} $$
- Debido a que usa los 4 valores vamos a expresar la misma fórmula usando Especificidad, Sensibilidad y Prevalencia. Esto se hace ya que así podremos usar la prevalencia que queramos y no la de nuestros datos.
$$ Accuracy=P(Predicción \; correcta|Predicción \; realizada) $$
- Eso se puede expresar como la suma de 2 probabilidades
$$ P(Predicción \; correcta|Predicción \; realizada)=P(Positivo \cap Enfermo) + P(Negativo \cap Sano)= $$
$$ P(Positivo|Enfermo)*P(Enfermo)+P(Negativo|Sano)*P(Sano)=Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia) $$
- Por lo tanto la fórmula que como:
$$ Accuracy=Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia) $$
- Vamos a ver que para la prevalencia de los datos, las 2 fórmulas son iguales.
$$ Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia)=\frac{TP}{(TP+FN)}*\frac{(TP+FN)}{TP+FN+FP+TN}+\frac{TN}{(FP+TN)}*\frac{(FP+TN)}{TP+FN+FP+TN}= $$
$$ \frac{TP}{TP+FN+FP+TN}+\frac{TN}{TP+FN+FP+TN}=\frac{TP+TN}{TP+FN+FP+TN}=Accuracy $$
Balanced Accuracy
Realmente esta no es una nueva métrica sino que es la misma que Accuracy pero con una prevalencia del 0.5
$$ Balanced \; Accuracy=\frac{Sensibilidad+Especificidad}{2} $$
- Pero si calculamos Accuracy suponiendo que la $Prevalencia=0.5$ obtenemos:
$$ Accuracy=Sensibilidad*Prevalencia+Especificidad*(1-Prevalencia)= $$
$$ Sensibilidad*0,5+Especificidad*(1-0,5)=Sensibilidad*0,5+Especificidad*0,5= $$
$$ \frac{Sensibilidad}{2}+\frac{Especificidad}{2}=\frac{Sensibilidad+Especificidad}{2}=Balanced \; Accuracy $$
Informedness o Indice Youden
Es la suma de la sensibilidad más la especificidad menos 1.
$$ Informedness=sensibilidad+especificidad-1 $$
Mas información:
- Youden Index and the optimal threshold for markers with mass at zero: El indice Youden es el máximo Informedness según el threshold
- Youden-Index for rating diagnostic tests: Explicación del índica Informedness o indice Youden
Para elegir cual es el mejor threshold posible a veces se usa el threshold que genera el mayor valor de Informedness
$$ Threhold que máximiza \{ sensibilidad(threhold)+especificidad(threhold)-1 \} \;\; threshold \in [0,1] $$
Area under the curve (AUC)
La Area under the curve (AUC) es una métrica que nos dice el área de una curva ROC. Pero pasemos primero a explicar que es una curva ROC.
Lo primero es que cuando predecimos que ciertos valores son Positivos o Negativos, lo hacemos en base a un umbral. Normalmente si algo es menor o igual que 0.5 decimos que es Negativo y si es mayor que 0.5 decimos que es Positivo. Pero ese umbral es arbitrario.
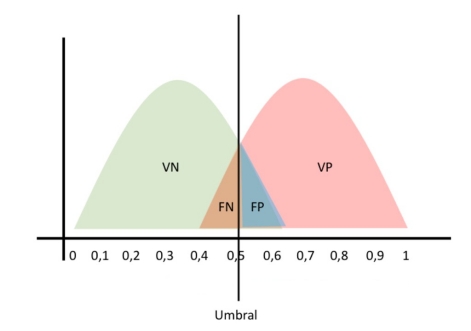
La siguiente imagen muestra la distribución de valores que hemos definido como presuntamente Positivos y los presuntamente Negativos. Si superan ese umbral se convierten en Falsos Positivos o Falsos Negativos.
En las siguientes gráficas vamos a ver como afecta a nuestro modelo el variar el umbral.
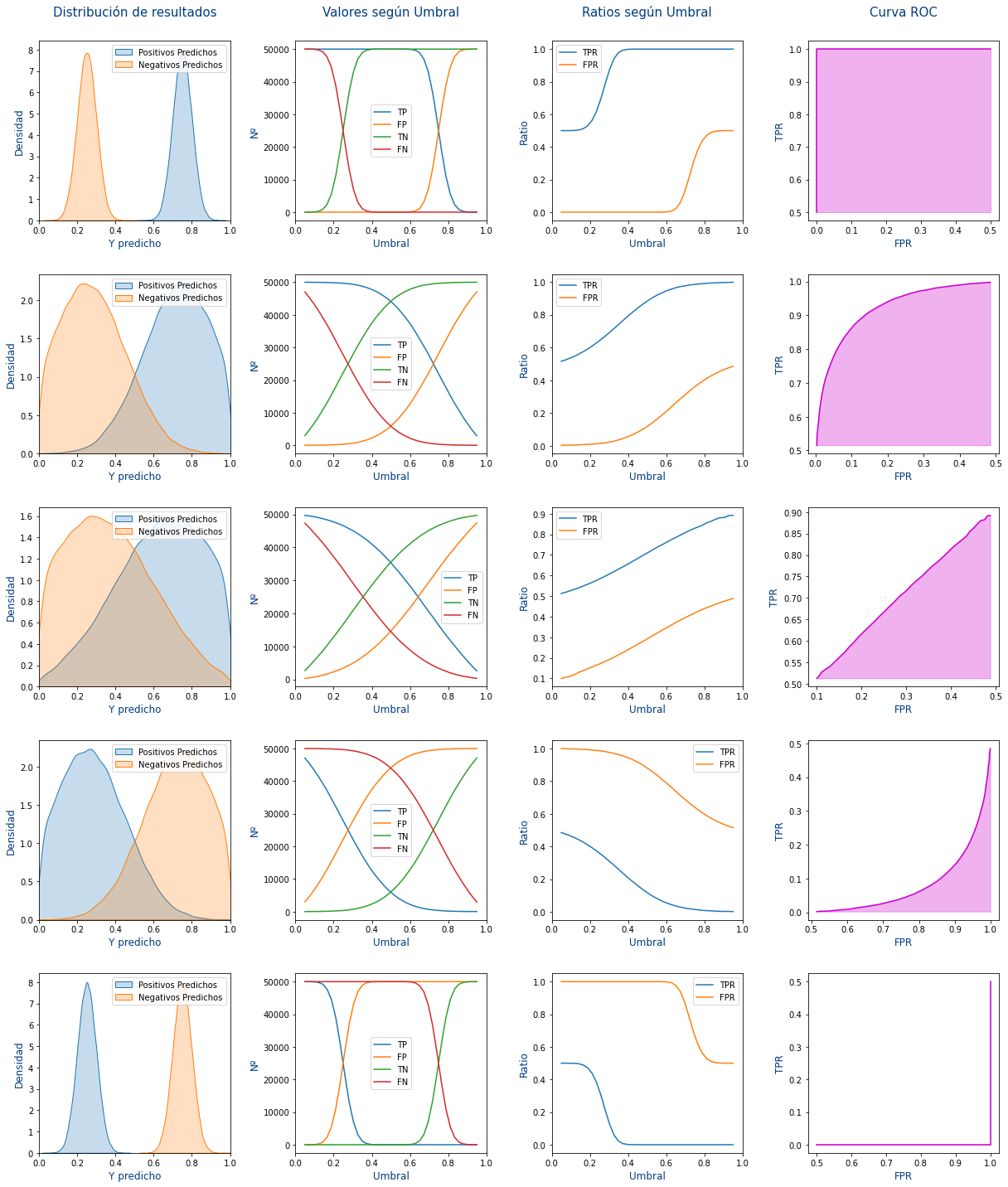
Vamos a explicar cada columna de la imagen anterior:
- 1º Columna: Se muestra la distribución de los Positivos y los Negativos que ha hecho el modelo. Pero según el umbral podrán ser True Positive (TP), True Negative (TN),False Positive (FP) y False Negative (FN)
- 2º Columna: Se muestra como evolucionan los True Positive (TP), True Negative (TN),False Positive (FP) y False Negative (FN) según se modificara el umbral. Para ello para cada umbral entre 0 y 1:
- Se cuenta cuantos Positivos hay bajo el umbral que serán los False Positive (FP)
- Se cuenta cuantos Positivos hay sobre el umbral que serán los True Positive (TP)
- Se cuenta cuantos Negativos hay bajo el umbral que serán los True Negative (TN)
- Se cuenta cuantos Negativos hay sobre el umbral que serán los False Negative (FN)
- 3º Columna: Se calculan las métricas de True Positive Rate (TPR) y False Positive Rate (FPR) según las siguientes fórmulas:
\begin{align} True \: Positive \: Rate \: (TPR) &= \frac{TP}{TP+FN} \\ False \: Positive \: Rate \: (FPR) &= \frac{FP}{FP+TN} \end{align}
- 4º Columna: Muestra el True Positive Rate (TPR) frente a False Positive Rate (FPR). Es decir que cada punto la
Xde la gráfica es el FPR y laYde la gráfica es el TPR.
Cada una de las filas de la imagen son predicciones distintas, siendo:
- 1º Fila: Una predicción perfecta.
- 2º Fila: Una predicción buena
- 3º Fila: Una predicción mala en la que falla lo mismo que acierta. Sería como hacerlo aleatorio con un 50% de probabilidades de acertar.
- 4º Fila: Una predicción nefasta que falla la mayoría de las veces.
- 5º Fila: Una predicción lamentable que nunca acierta.
Entonces, ¿Que es la Area under the curve (AUC)? Es el área de la curva ROC es decir el área rosa de las gráficas de la última columna. Si nos fijamos cuanto mejor es la predicción, mayor es el área rosa y por lo tanto mayor es la métrica de AUC.
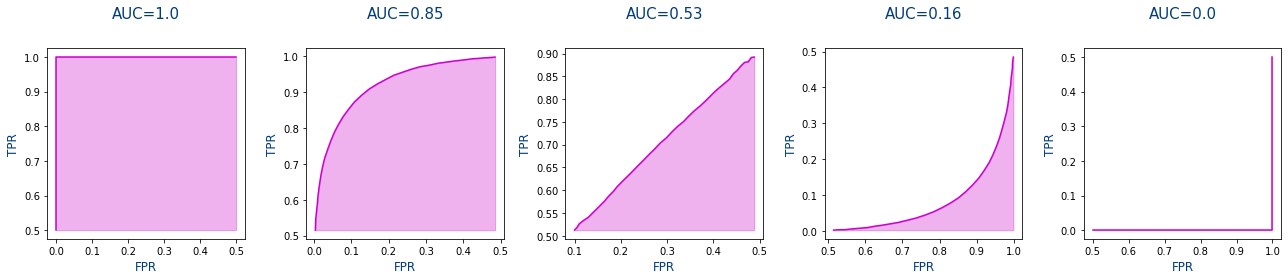
Destacar que se hace uso de la métrica AUC que es una métrica como cualquier otra que tiende a 1 si es buena y a 0 si es mala pero lo que no vas a ver al usar la métrica de AUC es la curva ROC. La curva ROC se muestra para entender que significa la métrica AUC pero no se dibuja normalmente.
En keras podemos usar la métrica de AUC de la siguiente forma: Su uso en Keras es
metrics=[tf.keras.metrics.AUC()] metrics=["AUC"]
y usarla como
history.history['auc'] history.history['val_auc']
Con sklearn podemos usar la métrica de AUC de la siguiente forma:
from sklearn.metrics import roc_auc_score auc=roc_auc_score(y_true,y_score)
Mas información:
- Cálculo del mejor Threshold:
Hay otra curva que en vez de ser (1-Especificidad) vs Sensibilidad , es la de Sensibilidad vs Precisión (llamada en inglés Precision-Recall) que se usa cuando los datos tienen una baja prevalencia.
Y además está relacionado con el F1-score ya que el F1-score se calcula justamente con la Sensibilidad y Precisión
- F1-score y ROC
Juntado dos Métricas derivadas
Las 4 métricas derivadas son PPV, NPV, FDR y FOR.
Markdness
Es la suma de la PPV más la NPV menos 1.
$$ Markdness=PPV+NPV-1 $$
Métricas mixtas
Son métricas que juntan una métrica básica con una métrica derivada.
F1-score
Es la media armónica entre Sensibilidad y Precision que permite combinar en una única métrica ambos valores. Se ha usado la media armónica ya que tiende atener un valor muy bajo para valores bajos. Por ello no se "cancelan" valores buenos de Sensibilidad con valores malos de Precision ya que en ese caso F1-score tenderá a ser bajo por lo que indicará que nuestro modelo es malo.
$$F1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}$$
Pero si sumamos las fracciones y hacemos la división:
$$F1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}= \frac{2}{\frac{Precision}{Sensibilidad \cdot Precision}+\frac{Sensibilidad}{Precision \cdot Sensibilidad}}= \frac{2}{\frac{Precision+Sensibilidad}{Sensibilidad \cdot Precision}} = \frac{2}{1}: \frac{Precision+Sensibilidad}{Sensibilidad \cdot Precision} = \frac { 2 \cdot Sensibilidad \cdot Precision}{Sensibilidad + Precision}$$
Siendo el resultado la formula que se ve como definición de F1-score:
$$F1{\text -}score=2 \cdot \frac {Sensibilidad \cdot Precision}{Sensibilidad + Precision}$$
Y por otro lado , podemos definir la fórmula en función de Sensibilidad , Especificidad y Prevalencia.
$$F1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}=$$ $$\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{\frac{Sensibilidad*Prevalencia}{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}}}=$$ $$\frac{2}{\frac{1}{Sensibilidad}+{\frac{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2}{\frac{1}{\frac{Sensibilidad*Prevalencia}{Prevalencia}}+{\frac{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2}{{\frac{Prevalencia}{Sensibilidad*Prevalencia}}+{\frac{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2}{{\frac{Prevalencia+Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2*Sensibilidad*Prevalencia}{Prevalencia+Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}=$$ $$\frac{2*Sensibilidad*Prevalencia}{Prevalencia+Sensibilidad*Prevalencia+1-Prevalencia-Especificidad+Especificidad*Prevalencia}=$$ $$\frac{2*Sensibilidad*Prevalencia}{Prevalencia*(1+Sensibilidad-1+Especificidad)+1-Especificidad}=$$ $$F1{\text -}score=\frac{2*Sensibilidad*Prevalencia}{Prevalencia*(Sensibilidad+Especificidad)+(1-Especificidad)}$$
clase/iabd/pia/2eval/tema07.metricas_derivadas.txt · Última modificación: 2024/03/25 14:47 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
