Herramientas de usuario
Barra lateral
clase:iabd:pia:2eval:tema07-apendices
Tabla de Contenidos
¡Esta es una revisión vieja del documento!
7. Entrenamiento de redes neuronales d) Apéndices
Tipos de funciones de coste
Huber
La función de coste Huber es un compromiso entre MAE y MSE, ese compromiso se define con un parámetro llamado delta $\delta$. La siguiente gráfica compara MAE, MSE y distintos valores de delta.
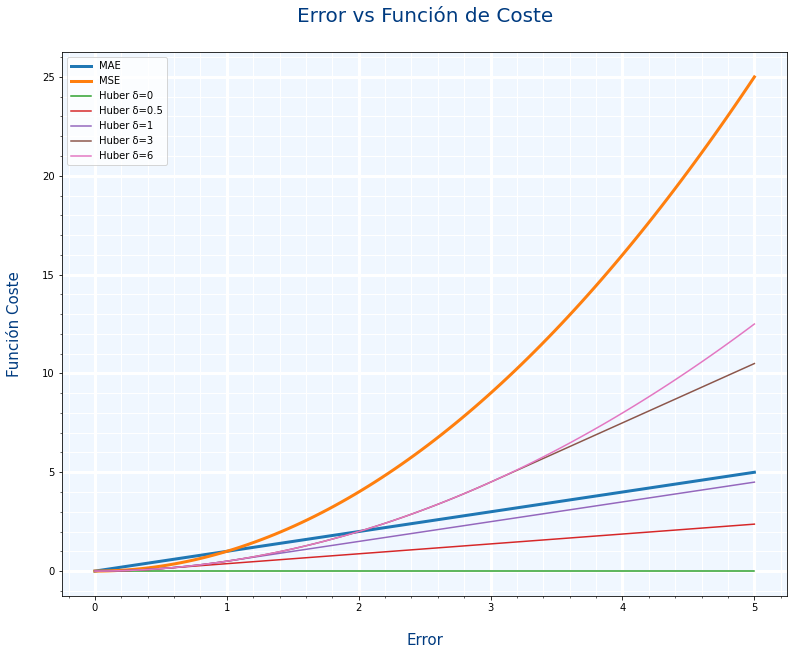
- Si delta tiene en valor cercano a 1, tenderá a parecerse a MAE
- Si delta tiene un valor elevado, tenderá a parecerse a MSE
Como decíamos con MAE y MSE. ¿queremos que los valores extremos se tengan en cuenta. Pues con el parámetro delta podemos hacer un ajuste mas fino
Su uso en Keras es:
model.compile(loss=tf.keras.losses.Huber(delta=3))
Pensando en la gráfica de Huber he pensado si $MAE=|y-\hat{y}|^1 $ y $MSE=|y-\hat{y}|^2$, en vez de usar Huber, ¿No podríamos usar como función de coste algo también intermedio como $MSE=|y-\hat{y}|^{1.5}$
Y he creado una gráfica similar para ver los resultados y no están mal
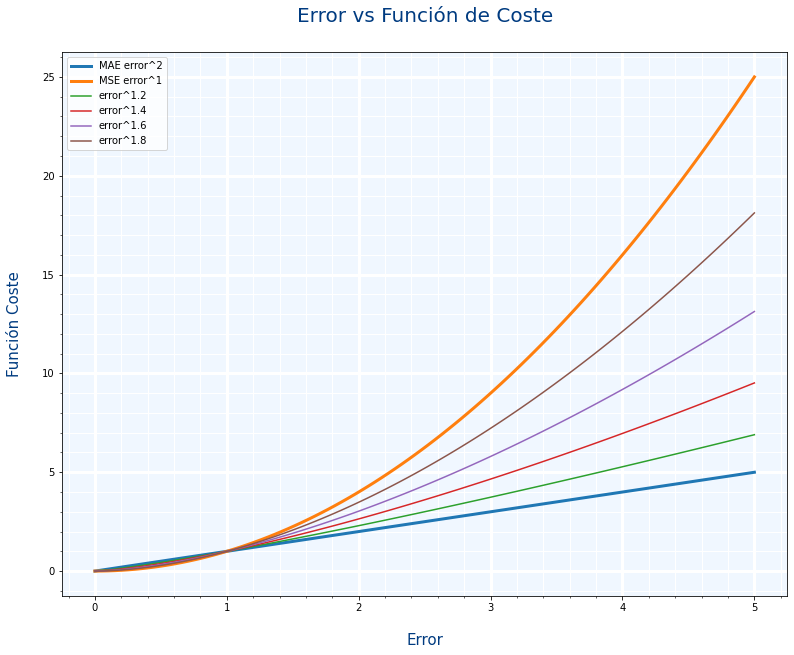
He mirado un poco por internet para ver si alguien los usaba y no he encontrado nada, supongo que será porque hacer el cálculo de una potencia con decimales es bastante costoso en tiempo.
Mas información:
Backpropagation
El Backpropagation es el algoritmo que optimiza el entrenamiento de la red. Calcular el gradiente (o derivada) de toda la red es muy costoso. Se basa en la idea de que los parámetros de una capa no dependen de la capa anterior.
Si volvemos a ver nuestra red neuronal de ejemplo, podemos calcular los pesos de la neurona 5 sin que influya en como van a ser los pesos de las neuronas 2, 3 y 4. Es decir que empezamos con las neuronas de las capas más hacía la salida y una vez calculados sus pesos , calculamos los parámetros de las capa anterior (más hacia la entrada) , y eso significa ir hacia atrás o backpropagation.
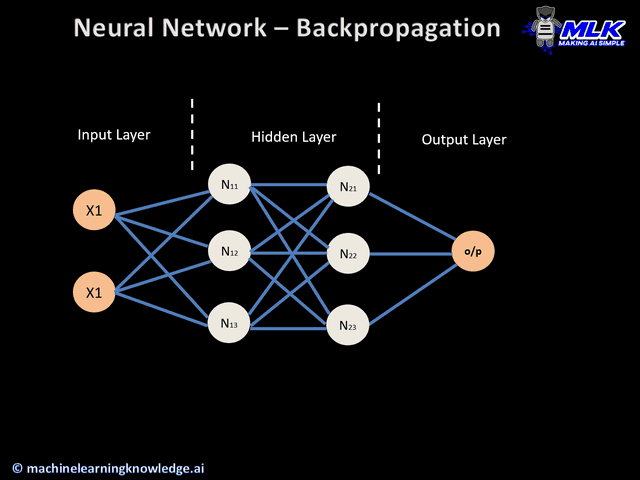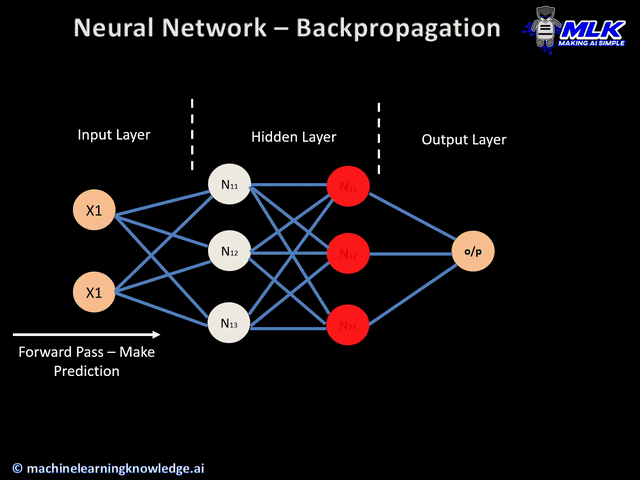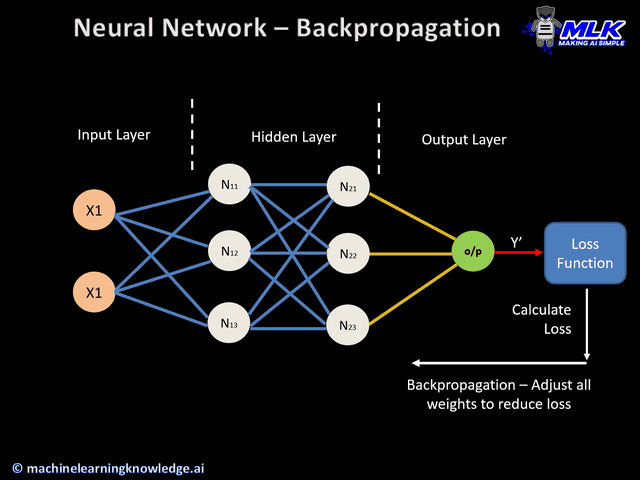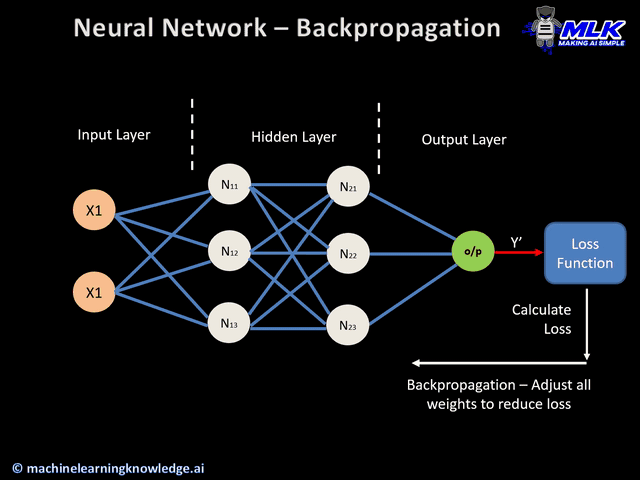
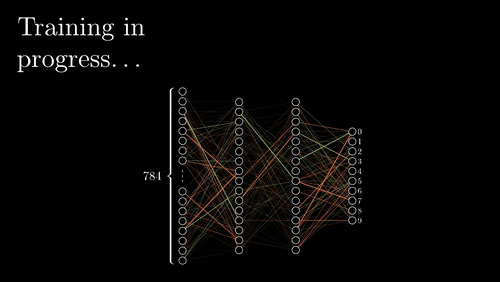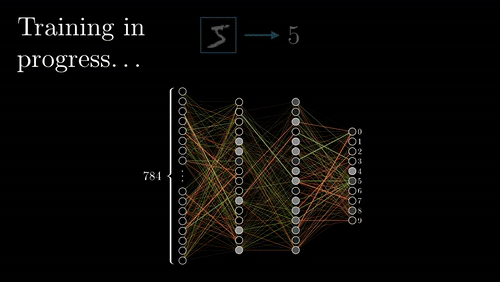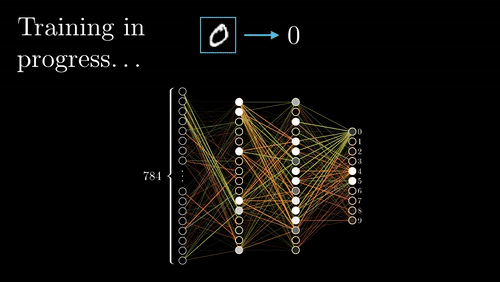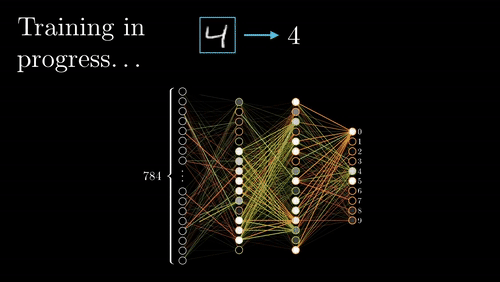
Con backpropagation acabamos de ver el orden en el que se calculan los parámetros de cada neurona y a continuación vamos a ver con el descenso de gradiente como calculamos los parámetros de una neurona.
Junto con el backpropagation aparece otro concepto llamado regla de la cadena o chain rule que se usa para junto al backpropagation para hacer menos cálculos. Está relacionado con el cálculo de derivadas.
En los siguientes videos está explicado perfectamente el backpropagation y la chain rule:
Creación de los gráficos del descenso de gradiente
Pasemos ahora a ver como se programa todo ésto en python.
Como ejemplo vamos a seguir la siguiente función:
$$ loss=3(1-w_0)^2e^{-w_0^2-(w_1+1)^2}-10(\frac{w_0}{5}-w_0^3-w_1^5)e^{-w_0^2-w_1^2}-\frac{1}{3}e^{-(w_0+1)^2-w_1^2} $$
cuya gráfica es la siguiente:
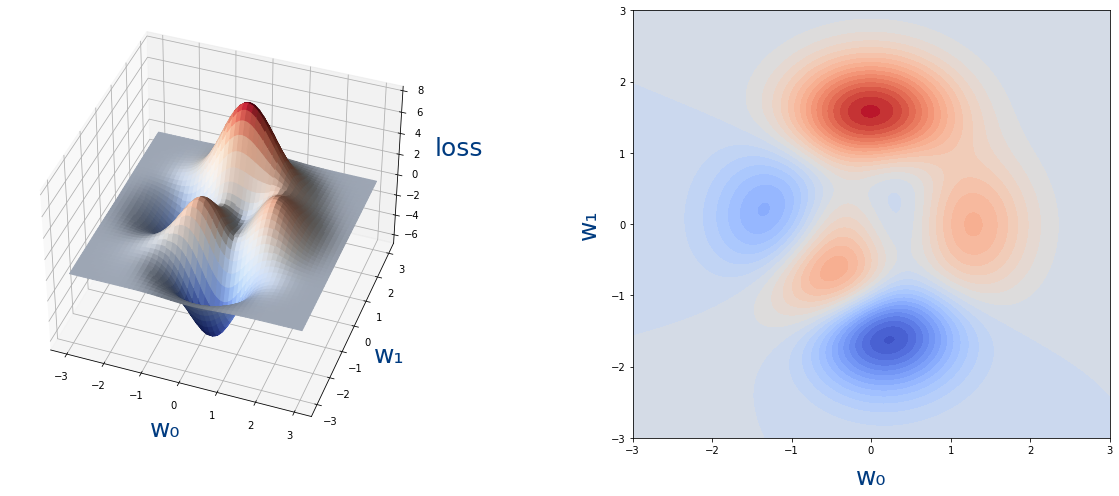
El siguiente código python es el algoritmo que acabamos de ver para saber por donde iríamos en nuestro viaje del descenso de gradiente.
def loss(w_0,w_1):
return 3*(1 - w_0)**2 * np.exp(-w_0**2 - (w_1 + 1)**2) - 10*(w_0/5 - w_0**3 - w_1**5)*np.exp(-w_0**2 - w_1**2) - 1./3*np.exp(-(w_0 + 1)**2 - w_1**2)
def get_puntos_descenso_gradiente(w_0_init,w_1_init,learning_rate,steps):
puntos_descenso_gradiente=np.array([[w_0_init,w_1_init]])
w_0=w_0_init
w_1=w_1_init
for i in range(steps):
h=0.00001
derivada_w_0=(loss(w_0+h,w_1)-loss(w_0,w_1))/h
derivada_w_1=(loss(w_0,w_1+h)-loss(w_0,w_1))/h
#Nuevos valores de los pesos
w_0=w_0-learning_rate*derivada_w_0
w_1=w_1-learning_rate*derivada_w_1
puntos_descenso_gradiente=np.append(puntos_descenso_gradiente,[[w_0,w_1]], axis=0)
return puntos_descenso_gradiente
Si lo ejecutamos con los siguientes datos
\begin{align} w_0 &= -0.35 \\ w_1 &= -0.67 \\ learning \: \: rate &= 0.03 \\ steps &= 5 \end{align}
La variable
steps dices cuantas veces se ejecuta el algoritmo o cuantos pasos debemos dar antes de pararnos.
En Keras los steps lo hemos visto como el parámetro epochs del método fit. No es exactamente lo mismo pero su objetivo es el mismo
Es decir llamando a la función así:
get_puntos_descenso_gradiente(-0.35,-0.67,0.03,5)
Saldría la siguiente imagen:
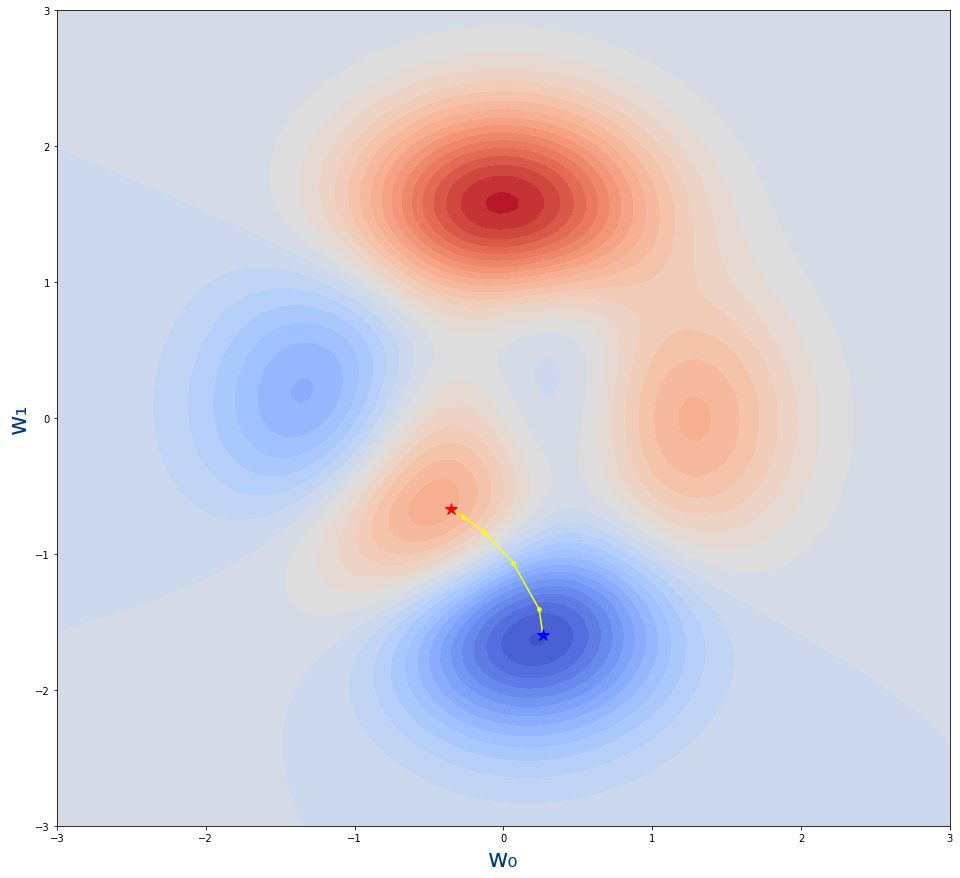
- La estrella roja es desde donde empieza el algoritmo.
- La estrella azul es donde acaba el algoritmo
- Los puntos amarillo son los pasos por lo que se va moviendo el algoritmo
Para poder hacer estas gráficas, hemos creado 2 funciones:
plot_loss_function: Que dibuja la superficie con todos los coloresplot_descenso_gradiente: Dibuja por donde va pasando el algoritmo del descenso de gradiente
def plot_loss_function(axes,fontsize=25,title=""):
rango_w_0=np.linspace(-3,3,100)
rango_w_1=np.linspace(-3,3,100)
rango_w_0,rango_w_1=np.meshgrid(rango_w_0,rango_w_1)
loss=loss_function(rango_w_0,rango_w_1)
axes.contourf(rango_w_0,rango_w_1,loss,30,cmap="coolwarm")
axes.set_xlabel('w₀',fontsize=fontsize,color="#003B80")
axes.set_ylabel('w₁',fontsize=fontsize,color="#003B80")
axes.set_title(title)
def plot_descenso_gradiente(axes,puntos_descenso_gradiente):
axes.scatter(puntos_descenso_gradiente[1:-1,0],puntos_descenso_gradiente[1:-1,1],13,color="yellow")
axes.plot(puntos_descenso_gradiente[:,0],puntos_descenso_gradiente[:,1],color="yellow")
axes.plot(puntos_descenso_gradiente[0,0],puntos_descenso_gradiente[0,1],"*",markersize=12,color="red")
axes.plot(puntos_descenso_gradiente[-1,0],puntos_descenso_gradiente[-1,1],"*",markersize=12,color="blue")
Y ahora el programa que usa las 4 funciones y que dibuja la gráfica es el siguiente:
figure=plt.figure(figsize=(16,15)) axes = figure.add_subplot() plot_loss_function(axes) plot_descenso_gradiente(axes,get_puntos_descenso_gradiente(-0.35,-0.67,0.03,5))
clase/iabd/pia/2eval/tema07-apendices.1647543528.txt.gz · Última modificación: 2022/03/17 19:58 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
