Herramientas de usuario
−Barra lateral
clase:iabd:pia:1eval:tema06-apendices
−Tabla de Contenidos
6. Redes neuronales: Apendices
Inicialización de parámetros
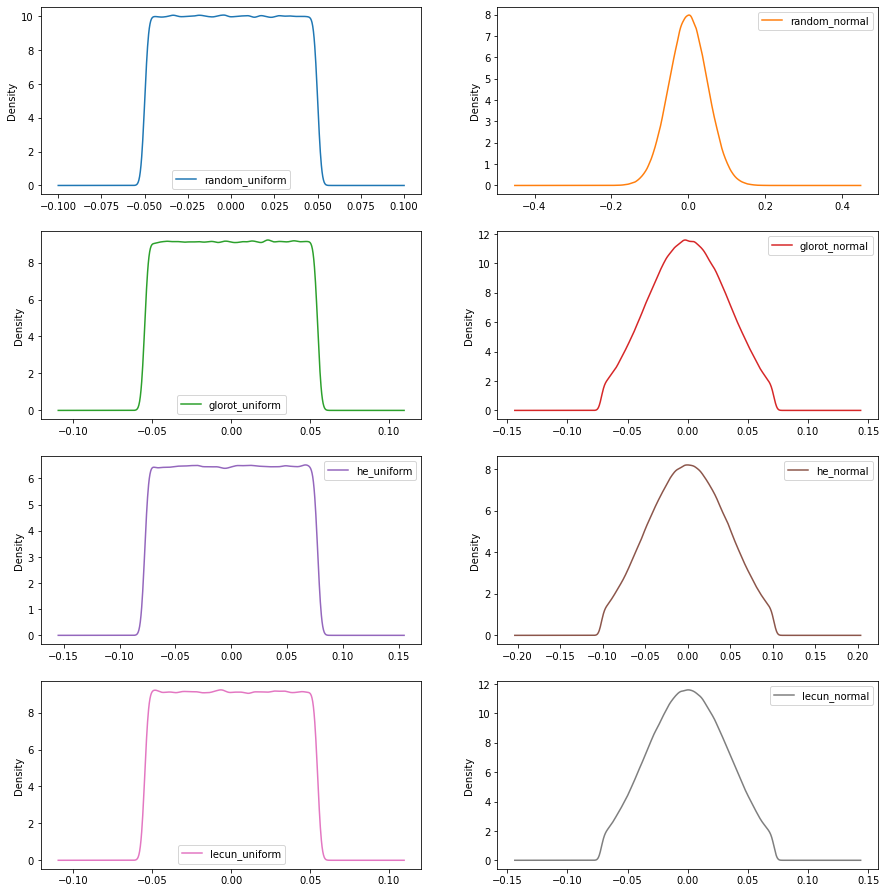
El siguiente código en Python nos muestra las funciones de distribución de cada uno de los inicializadores. El ejemplo no tiene utilidad real mas allá de mostrar los datos y las gráficas de los inicializadores.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import tensorflow as tfimport keras as kerasfrom keras.models import Sequentialfrom keras.layers import Denseimport pandas as pdinitializers=["random_uniform","random_normal","glorot_uniform","glorot_normal","he_uniform","he_normal","lecun_uniform","lecun_normal","zeros","ones"]model=Sequential()for initializer in initializers: model.add(Dense(1000, input_dim=1000,kernel_initializer=initializer))model.add(Dense(1000))model.compile()df=pd.DataFrame()for index,initializer in enumerate(initializers): pesos=(model.layers[index].get_weights()[0]).reshape(-1) df[initializer]=pesosdf.describe()df.iloc[:,0:8].plot(kind = 'density', subplots = True, layout = (5,2),figsize=(15,20),sharex = False) |
random_uniform random_normal glorot_uniform glorot_normal he_uniform he_normal lecun_uniform lecun_normal zeros ones count 1000000.000000 1000000.000000 1000000.000000 1000000.000000 1000000.000000 1000000.000000 1000000.000000 1000000.000000 1000000.0 1000000.0 mean -0.000022 -0.000005 -0.000010 0.000020 0.000054 0.000019 -0.000008 -0.000040 0.0 1.0 std 0.028850 0.049970 0.031639 0.031590 0.044715 0.044714 0.031611 0.031635 0.0 0.0 min -0.050000 -0.238984 -0.054772 -0.071899 -0.077459 -0.101682 -0.054772 -0.071899 0.0 1.0 25% -0.025000 -0.033713 -0.027437 -0.022938 -0.038669 -0.032442 -0.027381 -0.023074 0.0 1.0 50% -0.000047 0.000047 -0.000014 0.000056 0.000099 0.000064 0.000006 -0.000038 0.0 1.0 75% 0.024980 0.033729 0.027406 0.022980 0.038725 0.032528 0.027364 0.022952 0.0 1.0 max 0.050000 0.232416 0.054772 0.071900 0.077460 0.101682 0.054772 0.071900 0.0 1.0
Ahora vamos a ver como se comportan 4 redes distintas según el número de capas, el inicializador y la función de activación usada

Mas información:
- Hyper-parameters in Action! Part II — Weight Initializers: Demostración sencilla de las fórmulas de Glorot y He.
- Kaiming He initialization: Demostración del inicializador He
- Artículos académicos originales sobre Glorot, He y LeCun:
- Understanding the difficulty of training deep feedforward neural networks: Artículo original de Xavier Glorot sobre su inicializador.
- Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification: Artículo original de Kaiming He sobre su inicializador.
- Efficient BackProp: Artículo original de Yann LeCun sobre su inicializador.
- Artículos académicos sobre la importancia de la inicialización en distintas redes:
Usando funciones de activación en Keras
Funciones personalizadas
Podemos crear nuestra propia función de activación
1 2 3 4 5 |
from tensorflow.keras import backend as Kdef my_relu(x): return K.maximum(0.3*x, x) |
Y usarla de las siguientes formas
- Usando directamente la función de activación
1 |
model.add(Dense(3, input_dim=1,activation=my_relu)) |
- Creando una capa de activación en base a la función de activación con tf.keras.layers.Activation o tf.keras.layers.Lambda
1 2 |
model.add(Dense(3, input_dim=1))model.add(Dense(3, input_dim=1,activation=tf.keras.layers.Activation(my_relu))) |
1 2 |
model.add(Dense(3, input_dim=1))model.add(Dense(3, input_dim=1,activation=tf.keras.layers.Lambda(my_relu))) |
Funciones personalizadas parametrizadas
Pero si nuestra función tiene un parámetro
1 2 3 4 5 |
from tensorflow.keras import backend as Kdef my_relu(x,alpha): return K.maximum(alpha*x, x) |
Solo podremos usar tf.keras.layers.Lambda
1 2 |
model.add(Dense(3, input_dim=1))model.add(tf.keras.layers.Lambda(lambda x: my_relu(x,0.3))) |
Funciones con nombre
Para acabar vamos a ver como poder usar el nombre en una capa que nos hayamos creado nosotros usando el método tf.keras.utils.get_custom_objects
Vamos a definir un nombre de función de activación llamado relu_0_3 usando get_custom_objects()
1 2 3 4 5 6 7 |
from tensorflow.keras import backend as Kfrom tensorflow.keras.utils import get_custom_objectsdef my_relu(x,alpha): return K.maximum(alpha*x, x)get_custom_objects()['relu_0_3']=tf.keras.layers.Lambda(lambda x: my_relu(x,0.3)) |
Y simplemente lo usamos indicando el nombre de relu_0_3
1 |
model.add(Dense(3, input_dim=1,activation="relu_0_3")) |
Tipos de funciones de activación en capas ocultas
sigmoid
La fórmula de la sigmoide se obtiene a partir de la función logit o logodds.
odds(p)=p1−p logit(p)=log(odds(p))=log(p1−p)
Ahora:
logit(p)=ax+b log(p1−p)=ax+b
Si despejamos p de la anterior fórmula:
log(p1−p)=ax+belog(p1−p)=eax+bp1−p=eax+bp=eax+b⋅(1−p)p=eax+b−peax+bp+peax+b=eax+bp(1+eax+b)=eax+bp=eax+b1+eax+bp=eax+beax+b1+eax+beax+bp=11+1eax+bp=11+e−(ax+b)
Que es exactamente la función sigmoide
- Más información
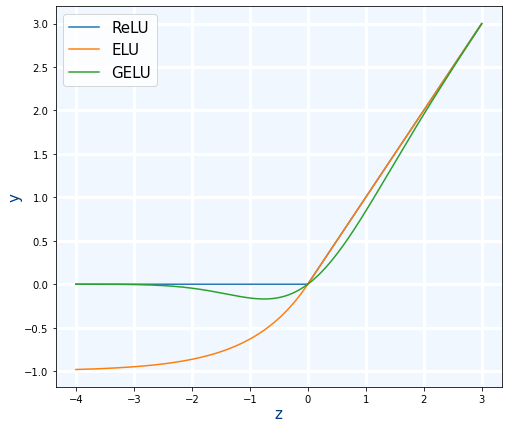
ReLU y Leaky ReLU
Ahora vamos a complicarlo un poco. Resulta que la función de activación tf.keras.activations.relu tiene un parámetro llamado alpha que hace que comporte como la función Leaky ReLU. Y también la capa tf.keras.layers.ReLU() tiene el mismo parámetro pero llamado negative_slope y obviamente hace exactamente lo mismo. Por lo tanto es igual a Leaky ReLU
1 2 |
model.add(Dense(3, input_dim=1,activation=tf.keras.layers.ReLU(negative_slope=0.3)))model.add(Dense(3, input_dim=1,activation=tf.keras.layers.Lambda(lambda x: tf.keras.activations.relu(x,alpha=0.3)))) |
Con el siguiente código podemos ver el resultado:
1 2 3 4 5 6 7 8 9 10 11 12 |
class_relu=tf.keras.layers.ReLU(negative_slope=0.3)class_leaky_relu=tf.keras.layers.LeakyReLU()x=np.linspace(-5,5,500)y_class_relu=class_relu(x)y_relu=tf.keras.activations.relu(x, alpha=0.3).numpy()y_class_leaky_relu=class_leaky_relu(x)np.set_printoptions(threshold=np.inf)np.set_printoptions(suppress=True)np.column_stack((y_relu,y_class_leaky_relu,y_class_relu,y_relu-y_class_leaky_relu,y_class_relu-y_class_leaky_relu)) |
Además en el código cuente de TensorFlow podemos ver como realmente son iguales:
PReLU
Existe otra capa de activación llamada PReLU que es similar a Leaky ReLU pero el valor de α se calcula automáticamente durante el entrenamiento, es decir que es como un parámetro mas de la red.
Mas información:
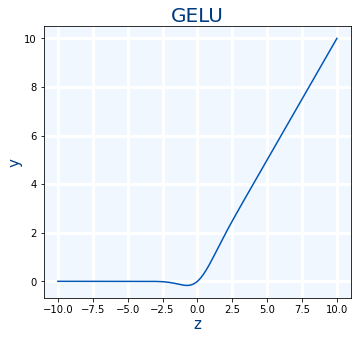
GELU
GELU es de la últimas funciones de activación "famosas" que han aparecido. GELU: Se usa con Transformers. La usa Google con BERT y OpenAI en GPT-2 y GPT-3.1)
GELU(x)=0.5x(1+2√π∫x√20e−t2dt)
- Uso en Keras
1 2 |
model.add(Dense(3, input_dim=1,activation=tf.keras.activations.gelu))model.add(Dense(3, input_dim=1,activation="gelu")) |
Mas información:
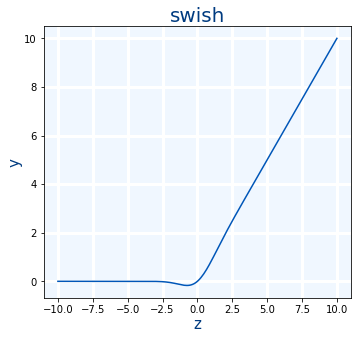
Swish
Se usa cuando ReLU pero es un poco más lenta pero es mejor.
swish(x)=x⋅sigmoid(x)=x⋅11+e−x=x1+e−x
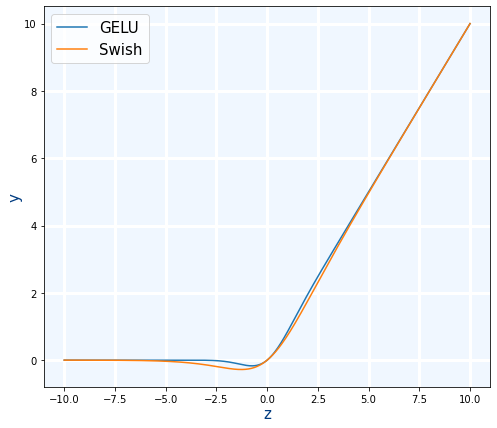
- Uso en Keras
1 2 |
model.add(Dense(3, activation=tf.keras.activations.swish))model.add(Dense(3, activation="swish")) |
- Swish: A Self-Gated Activation Function: Paper original de Swish
Mish
Se usa cuando ReLU pero aunque es un poco más lenta es mejor. Es muy similar a Swish
mish(x)=x⋅tanh(softplus(x))
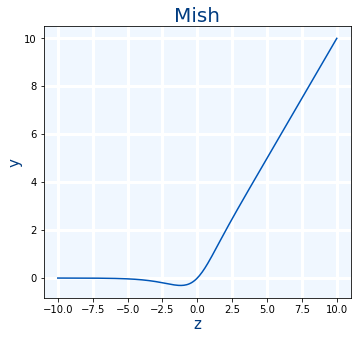
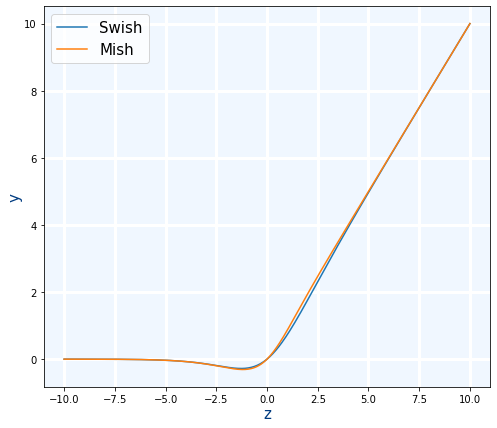
- Uso en Keras
1 2 |
model.add(Dense(3, activation=tf.keras.activations.swish))model.add(Dense(3, activation="mish")) |
- [https://www.tensorflow.org/api_docs/python/tf/keras/activations/mish|tf.keras.activations.mish(x)]]
- Mish: A Self Regularized Non-Monotonic Activation Function: Paper original de Mish
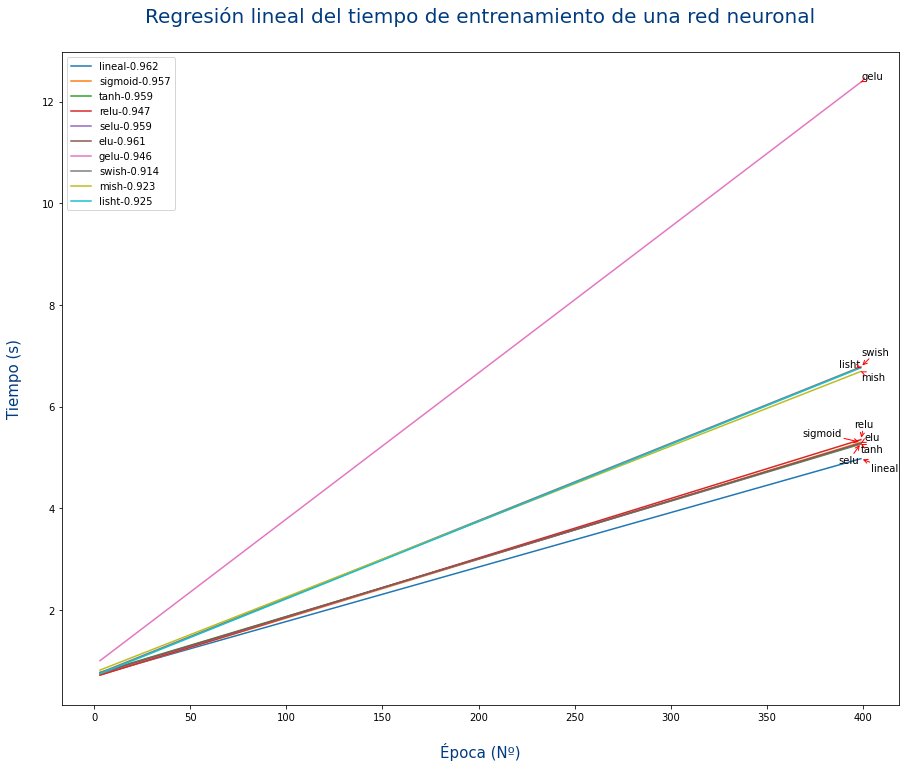
Tiempo de cálculo
Para cada problema puede que una función sea mejor que otra, es decir que cosiga entrenar en un menor número de épocas. Aun así a veces no puede preocupar el tiempo de CPU/GPU que usa cada función de activación.
En la siguiente gráfica se puede ver el tiempo de entrenamiento de una red neuronal con 14 capas y 1521 neuronas usando cada una de las funciones de activación.
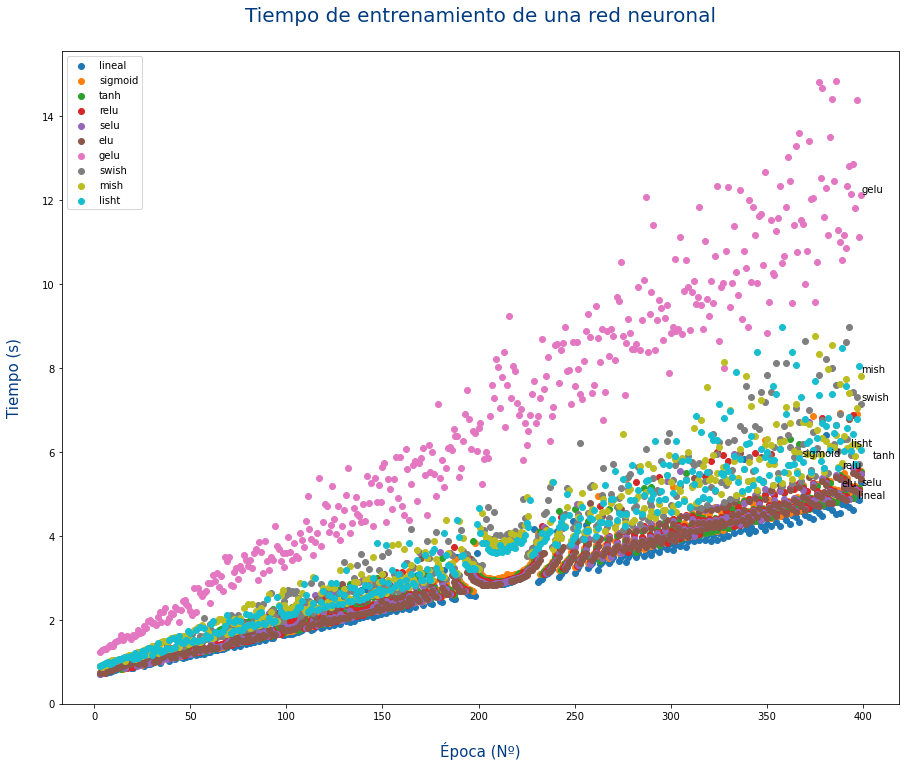
clase/iabd/pia/1eval/tema06-apendices.txt · Última modificación: 2024/01/06 11:58 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
