Herramientas de usuario
−Barra lateral
clase:iabd:pia:2eval:tema07-codigo
¡Esta es una revisión vieja del documento!
7.i Código
Durante el tema hemos visto los gráficos que explican el descenso de gradiente. Veamos ahora como se pueden hacer dichos gráficos en Python.
La función que coste que hemos usado es la siguiente
loss(w0,w1)=3(1−w0)2e−w20−(w1+1)2−10(w05−w30−w51)e−w20−w21−13e−(w0+1)2−w21
cuya gráfica es la siguiente:
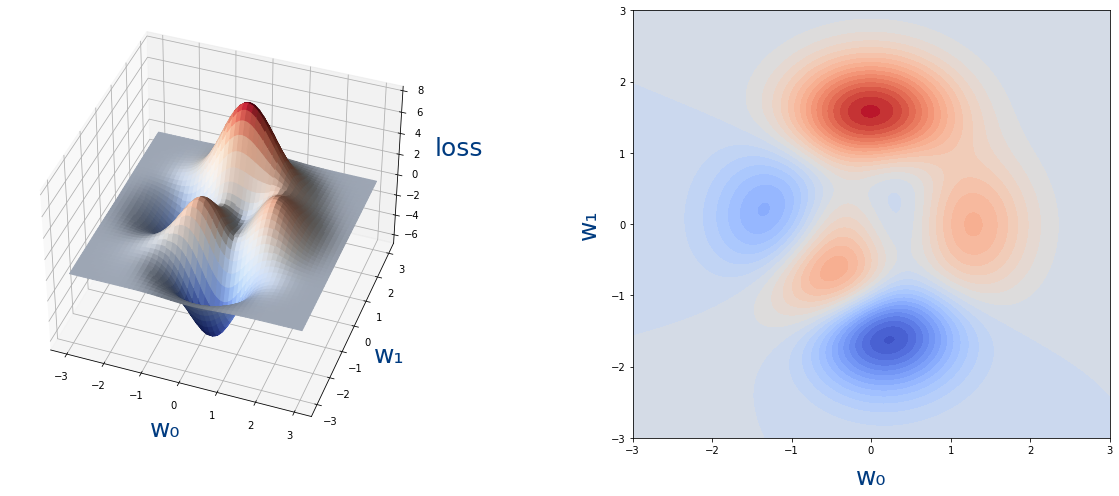
En python la función loss(w0,w1) con NumPy sería así:
1 2 |
def loss(w_0,w_1): return 3*(1 - w_0)**2 * np.exp(-w_0**2 - (w_1 + 1)**2) - 10*(w_0/5 - w_0**3 - w_1**5)*np.exp(-w_0**2 - w_1**2) - 1./3*np.exp(-(w_0 + 1)**2 - w_1**2) |
Y el algoritmo que calcula cada uno de los w0,w1 del descenso de gradiente es el siguiente:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def get_puntos_descenso_gradiente(epochs,learning_rate,w_0_original,w_1_original): w_0=w_0_original w_1=w_1_original puntos_descenso_gradiente=np.array([[w_0,w_1]]) for epoch in range(epochs): h=0.00001 gradiente_w_0=(loss(w_0+h,w_1)-loss(w_0,w_1))/h gradiente_w_1=(loss(w_0,w_1+h)-loss(w_0,w_1))/h #Nuevos valores de los pesos w_0=w_0-learning_rate*gradiente_w_0 w_1=w_1-learning_rate*gradiente_w_1 puntos_descenso_gradiente=np.append(puntos_descenso_gradiente,[[w_0,w_1]], axis=0) return puntos_descenso_gradiente |
Si ejecutamos lo siguiente:
1 |
get_puntos_descenso_gradiente(5,0.03,-0.35,-0.67) |
El resultado es:
array([[-0.35 , -0.67 ],
[-0.26931594, -0.72470447],
[-0.13292324, -0.838827 ],
[ 0.0654496 , -1.06459902],
[ 0.24087009, -1.40749396],
[ 0.2657862 , -1.59573582]])
Que son cada uno de los valores de w0,w1 que empiezan en -0.35, -0.67 y acaban en 0.2657862, -1.59573582$
Pasamos ahora a mostrar los valores dentro de la gráfica de la función, para ello hemos creado 2 funciones:
plot_loss_function: Que dibuja la superficie con todos los coloresplot_descenso_gradiente: Dibuja los puntos por donde va pasando el algoritmo del descenso de gradiente
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def plot_loss_function(axes,fontsize=25,title=""): rango_w_0=np.linspace(-3,3,100) rango_w_1=np.linspace(-3,3,100) rango_w_0,rango_w_1=np.meshgrid(rango_w_0,rango_w_1) loss=loss_function(rango_w_0,rango_w_1) axes.contourf(rango_w_0,rango_w_1,loss,30,cmap="coolwarm") axes.set_xlabel('w₀',fontsize=fontsize,color="#003B80") axes.set_ylabel('w₁',fontsize=fontsize,color="#003B80") axes.set_title(title)def plot_descenso_gradiente(axes,puntos_descenso_gradiente): axes.scatter(puntos_descenso_gradiente[1:-1,0],puntos_descenso_gradiente[1:-1,1],13,color="yellow") axes.plot(puntos_descenso_gradiente[:,0],puntos_descenso_gradiente[:,1],color="yellow") axes.plot(puntos_descenso_gradiente[0,0],puntos_descenso_gradiente[0,1],"*",markersize=12,color="red") axes.plot(puntos_descenso_gradiente[-1,0],puntos_descenso_gradiente[-1,1],"*",markersize=12,color="blue") |
Si ejecutamos el código:
1 2 3 4 5 |
figure=plt.figure(figsize=(16,15))axes = figure.add_subplot()plot_loss_function(axes)plot_descenso_gradiente(axes,get_puntos_descenso_gradiente(5,0.03,-0.35,-0.67)) |
Vemos la siguiente gráfica donde se muestran los puntos que hemos obtenido de la función get_puntos_descenso_gradiente
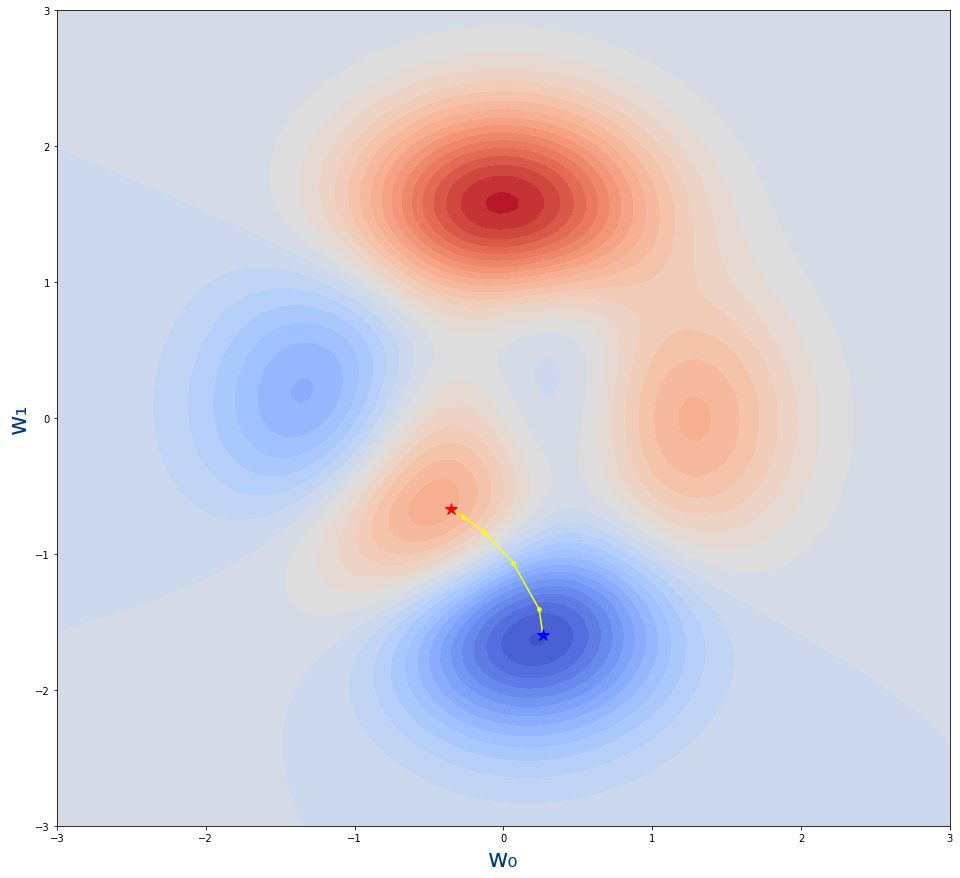
- La estrella roja es desde donde empieza el algoritmo.Es decir, el valor inicial de los parámetros w0,w1
- La estrella azul es donde acaba el algoritmo.Es decir, el valor tras el entrenamiento de los parámetros w0,w1
- Los puntos amarillo son los pasos por lo que se va moviendo el algoritmo. Cada uno de los valores intermedios de los parámetros durante el entrenamiento.
Optimizadores de Keras
Podemos mejorar nuestro código en Python haciendo que podamos usar directamente los Optimizers de Keras y de esa forma ver como funciona cada uno de ellos. Para poder usarlos directamente vamos a creas las nuevas funciones loss_tf y get_puntos_descenso_gradiente_optimizer adecuadas a TensorFlow y Keras.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def loss_tf(w_0,w_1): return 3*(1 - w_0)**2 * tf.exp(-w_0**2 - (w_1 + 1)**2) - 10*(w_0/5 - w_0**3 - w_1**5)*tf.exp(-w_0**2 - w_1**2) - 1./3*tf.exp(-(w_0 + 1)**2 - w_1**2) def get_puntos_descenso_gradiente_optimizer(epochs,optimizer_function,w_0_init,w_1_init): puntos_descenso_gradiente=np.array([[w_0_init,w_1_init]]) w_0=w_0_init w_1=w_1_init for epoch in range(epochs): var_w_0=tf.Variable(w_0) var_w_1=tf.Variable(w_1) optimizer_function.minimize(lambda: loss_tf(var_w_0,w_1), var_list=[var_w_0]) optimizer_function.minimize(lambda: loss_tf(w_0,var_w_1), var_list=[var_w_1]) w_0=var_w_0.numpy() w_1=var_w_1.numpy() puntos_descenso_gradiente=np.append(puntos_descenso_gradiente,[[w_0,w_1]], axis=0) return puntos_descenso_gradiente |
Lo que ha cambiado principalmente es la función get_puntos_descenso_gradiente_optimizer no hace cálculo del gradiente (derivada) ni actualiza los parámetros, sino que llama a la función de Keras de optimización.
Si usamos get_puntos_descenso_gradiente_optimizer ahora con tf.keras.optimizers.SGD
1 |
get_puntos_descenso_gradiente_optimizer(5,tf.keras.optimizers.SGD(learning_rate=0.03),-0.35,-0.67) |
array([[-0.35 , -0.67 ],
[-0.269319 , -0.72470832],
[-0.13292952, -0.83883744],
[ 0.06544246, -1.06462073],
[ 0.24086528, -1.40752137],
[ 0.26578248, -1.59573841]])
Vamos que el resultado es prácticamente el mismo que cuando lo hicimos manualmente.
Y podemos generar de la misma forma el gráfico:
1 2 3 4 5 |
figure=plt.figure(figsize=(16,15))axes = figure.add_subplot()plot_loss_function(axes)plot_descenso_gradiente(axes,get_puntos_descenso_gradiente_optimizer(5,tf.keras.optimizers.SGD(learning_rate=0.03),-0.35,-0.67)) |
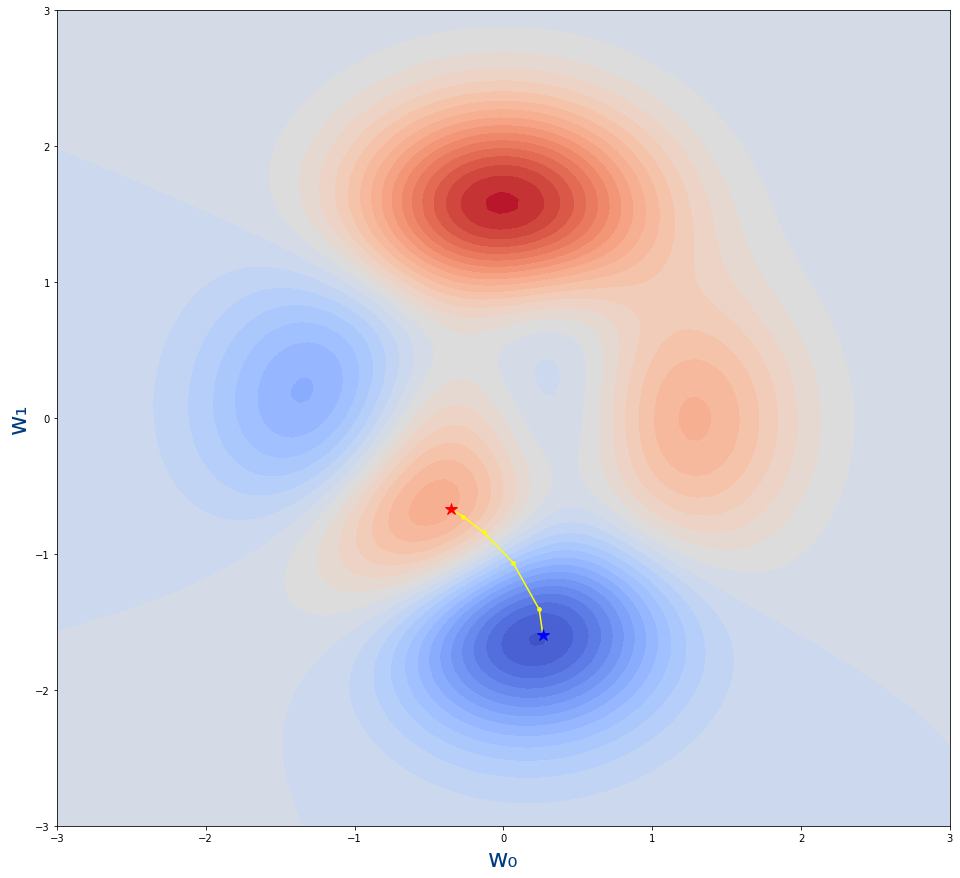
Y obviamente el resultado es el mismo
clase/iabd/pia/2eval/tema07-codigo.1730894977.txt.gz · Última modificación: 2024/11/06 13:09 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
