Herramientas de usuario
Barra lateral
clase:iabd:pia:2eval:tema08.metricas_derivadas
Tabla de Contenidos
8.c Métricas rendimiento general de clasificación
En este apartado vamos a ampliar las métricas que podemos usar con la clasificación binaria. Las métricas básicas ya las vimos en 8.b Métricas clasificación (Bayes). Pero ahora vamos a ver nuevas métricas que intentan resumir en un único número el rendimiento general de la red neuronal.
Las métricas que vamos a ver están en Matriz de confusión en Wikipedia.

Las métricas que ya las hemos explicado en el tema anterior son:
- Métricas básicas (Sensibilidad, Especificidad, FNR , FPR y Prevalencia)
- Métricas derivadas según el teorema de bayes (PPV,NPV, FDR y FOR)
Y ahora vamos a explicar las siguiente métricas:
- Métricas independientes de la prevalencia: Estas métricas solo usan sensibilidad y especificidad.
- Métricas de rendimiento global: Usan la prevalencia además de la sensibilidad y especificidad.
- Métricas para datos desbalaceados: No tienen en cuenta los verdaderos negativos.
La siguiente pregunta es ¿Que métrica debemos elegir? En el apartado siguiente 8.d Selección de métricas de clasificación vamos a explicar que métrica elegir en cada caso.
En esta página van a salir la media aritmética, la media geométrica o armónica. Para profundizar sobre que es la media se recomienda leer el artículo Qué es la media y cuál usar
Normalización
Hay indices como Matthews correlation coefficient (MCC) que tiene un rango de -1 a 1. Eso nos puede despistar al comparar valores. Así que en estos casos se creará crear un nuevo índice llamado Normalizado para que su rango de valores sea de 0 a 1.
En el caso de rangos de -1 a 1 simplemente habrá que sumar 1 al índice en cuestión y dividirlo entre dos.
$$ MCC \; Normalizado=nMCC=\frac{MCC+1}{2} $$
Fórmulas
Antes de explicar cada fórmula, ponemos ya, a modo de resumen, todas las fórmulas.
| Métricas independientes de la prevalencia | |
|---|---|
| Nombre | Fórmula |
| nInformedness | $$\frac{Sensibilidad+Especificidad}{2}$$ |
| Balanced Accuracy | $$\frac{Sensibilidad+Especificidad}{2}$$ |
| Prevalence threshold (PT) | $$\frac{\sqrt{1-Especificidad}}{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}}$$ |
| ROC-AUC | roc_auc=roc_auc_score(y_true,y_score) |
| Métricas de rendimiento global | |
|---|---|
| Nombre | Fórmula |
| Accuracy | $$Especificidad+(Sensibilidad-Especificidad) \cdot Prevalencia$$ |
| nMCC | $$\Large \frac{\frac{Sensibilidad+Especificidad-1}{\sqrt{ \frac{Prevalencia}{1-Prevalencia} Sensibilidad - Especificidad +1} \cdot \sqrt{ \frac{1-Prevalencia}{Prevalencia} Especificidad - Sensibilidad +1}}+1}{2}$$ |
| Markedness | $$\frac{VPP+VPN}{2}$$ |
| Métricas para datos desbalaceados | |
|---|---|
| Nombre | Fórmula |
| Jaccard | $$\frac{Precision \cdot Sensibilidad}{Precision+Sensibilidad-Precision \cdot Sensibilidad}=\frac{TP}{TP+FP+FN}$$ |
| F1-score | $$\frac { 2 \cdot Sensibilidad \cdot Precision}{Sensibilidad + Precision}=\frac{TP}{\frac{(TP+FP)+(TP+FN)}{2}}$$ |
| Fowlkes-Mallows (FM) | $$\sqrt{Sensibilidad*Precisión}=\frac{TP}{\sqrt{(TP+FP) \cdot (TP+FN)}}$$ |
| PR-AUC | pr_auc=average_precision_score(y_true,y_score) |
Informedness
Este índice pretende resumir los valores de sensibilidad y especificidad (también se puede llamar Indice Youden). Su fórmula es:
$$ Informedness=Sensibilidad+Especificidad-1 $$
Como vemos, es la suma de la sensibilidad más la especificidad menos 1. Eso hace que su rango sea de -1 a 1. En estos caso como ya hemos comentado en ese caso calcularemos el $Informedness \; normalizado$ o $nInformedness$ para que tenga un valor de 0 a 1
$$ Informedness \; Normalizado=nInformedness=\frac{Informedness+1}{2}=\frac{Sensibilidad+Especificidad}{2} $$
Es decir que el $nInformedness$ es simplemente la media aritmética de sensibilidad y especificidad. El cual no es un mal índice si desconocemos totalmente la prevalencia que nos vamos a encontrar.
Mas información:
- Youden-Index for rating diagnostic tests: Explicación del índica Informedness o indice Youden
Para elegir cual es el mejor threshold posible a veces se usa el threshold que genera el mayor valor de Informedness
$$ Threshold \; que \; máximiza \{ sensibilidad(threhold)+especificidad(threhold)-1 \} \;\; threshold \in [0,1] $$
Más información:
- Youden Index and the optimal threshold for markers with mass at zero: El indice Youden es el máximo Informedness según el threshold
Balanced Accuracy
Realmente esta no es una nueva métrica sino que es la misma que Accuracy pero con una prevalencia del 0.5
Si la fórmula de la $Accuracy$ en función de la prevalencia es: $$ Accuracy=Especificidad+(Sensibilidad-Especificidad) \cdot Prevalencia $$
Y suponiendo que la prevalencia está balanceada, es decir que $Prevalencia=0,5=\frac{1}{2}$
$$ Accuracy=Especificidad+(Sensibilidad-Especificidad) \cdot \frac{1}{2}= $$
$$ \frac{2 \cdot Especificidad}{2}+\frac{Sensibilidad-Especificidad}{2}= $$
$$ \frac{2 \cdot Especificidad+Sensibilidad-Especificidad}{2}= $$
$$ \frac{Sensibilidad+Especificidad}{2}=Balanced \; Accuracy $$
$$ Balanced \; Accuracy=\frac{Sensibilidad+Especificidad}{2} $$
Por eso se llama $Balanced \; Accuracy$ porque es suponiendo que la prevalencia es $0,5$. Pero si nos fijamos esta fórmula es exactamente la misma que la de $nInformedness$
$$ Balanced \; Accuracy=nInformedness=\frac{Sensibilidad+Especificidad}{2} $$
Prevalence threshold (PT)
El $Prevalence \; threshold \; (PT)$ es una métrica un poco extraña ya que lo que nos está diciendo es un valor de la prevalencia.
$$ Prevalence \; threshold \; (PT)=\frac{\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)}{Sensibilidad-(1-Especificidad)}=\frac{\sqrt{1-Especificidad}}{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}} $$
¿Y un valor de prevalencia es una métrica? Vamos a explicarlo con la siguiente gráfica:

En esta gráfica estamos viendo el valor de la precisión (VPP) en función de la prevalencia. En la gráfica de la izquierda para una $Sensibilidad=0.99$ y $Especificidad=0.99$ mientras que en la segunda gráfica para $Sensibilidad=0.01$ y $Especificidad=0.01$. Además en cada gráfica se ve el valor de una prevalencia que corresponde exactamente con el de Prevalence threshold (PT), en la gráfica izquierda el valor de $Prevalence \; threshold \; (PT)=0.99$ y en la gráfica de la derecha el valor de $Prevalence \; threshold \; (PT)=0.91$. Por ultimo en ambos casos hay una recta que va desde el punto (0,1) al punto (1,0) cuya ecuación es $y=1-Prevalencia$.
Una vez hemos explicado la información que sale en cada una de las gráficas, expliquemos que es el $Prevalence \; threshold \; (PT)$, es simplemente el valor de umbral donde se cortan las curvas de precisión y la recta que va de una esquina a otra. Para demostrarlo simplemente debemos igualar ambas curvas y despejar la prevalencia.
$$ Precisión=\frac{Sensibilidad \cdot Prevalencia}{Sensibilidad \cdot Prevalencia+(1-Expecificidad) \cdot (1-Prevalencia)} $$
$$ y=1-Prevalencia $$
Si igualamos ambas ecuaciones:
$$ \frac{Sensibilidad \cdot Prevalencia}{Sensibilidad \cdot Prevalencia+(1-Expecificidad) \cdot (1-Prevalencia)}=1-Prevalencia $$
Y si despejamos la prevalencia se obtiene:
$$ Prevalencia=\frac{\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)}{Sensibilidad-(1-Especificidad)}=\frac{\sqrt{1-Especificidad}}{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}} $$
Despejar la prevalencia paso a paso: (Pincha para ver todo el desarrollo matemático)
$$ \frac{Sensibilidad \cdot Prevalencia}{Sensibilidad \cdot Prevalencia+(1-Especificidad) \cdot (1-Prevalencia)}=1-Prevalencia $$
$$ Sensibilidad \cdot Prevalencia=(1-Prevalencia)[Sensibilidad \cdot Prevalencia+(1-Especificidad) \cdot (1-Prevalencia)] $$
$$ Sensibilidad \cdot Prevalencia=Sensibilidad \cdot Prevalencia+(1-Especificidad) \cdot (1-Prevalencia) \\ -Sensibilidad \cdot Prevalencia^2-(1-Especificidad) \cdot (1-Prevalencia) \cdot Prevalencia $$
$$ Sensibilidad \cdot Prevalencia+(1-Especificidad) \cdot (1-Prevalencia)-Sensibilidad \cdot Prevalencia^2 \\ -(1-Especificidad) \cdot (1-Prevalencia) \cdot Prevalencia-Sensibilidad \cdot Prevalencia=0 $$
$$ Sensibilidad \cdot Prevalencia+1-Prevalencia-Especificidad+Especificidad \cdot Prevalencia-Sensibilidad \cdot Prevalencia^2 \\ -(1-Especificidad) \cdot (1-Prevalencia) \cdot Prevalencia-Sensibilidad \cdot Prevalencia=0 $$
$$ Sensibilidad \cdot Prevalencia+1-Prevalencia-Especificidad+Especificidad \cdot Prevalencia-Sensibilidad \cdot Prevalencia^2 \\ -(1-Prevalencia-Especificidad+Especificidad \cdot Prevalencia) \cdot Prevalencia-Sensibilidad \cdot Prevalencia=0 $$ $$ Sensibilidad \cdot Prevalencia+1-Prevalencia-Especificidad+Especificidad \cdot Prevalencia-Sensibilidad \cdot Prevalencia^2 \\ -Prevalencia+Prevalencia^2+Especificidad \cdot Prevalencia-Especificidad \cdot Prevalencia^2 -Sensibilidad \cdot Prevalencia=0 $$
- Agrupamos y simplificamos términos
$$ 1-2 \cdot Prevalencia-Especificidad+2 \cdot Especificidad \cdot Prevalencia-Sensibilidad \cdot Prevalencia^2 \\ +Prevalencia^2-Especificidad \cdot Prevalencia^2 =0 $$
- Sacamos la prevalencia como factor común
$$ (1-Sensibilidad-Especificidad) \cdot Prevalencia^2+2 \cdot (Especificidad-1) \cdot Prevalencia+(1-Especificidad)=0 $$
- La fórmula para resolver ecuaciones de segundo grado es:
$$ ax^2+bx+c=0 $$
$$ x=\frac{-b \pm \sqrt{b^2-4ac}}{2a} $$
- Ahora aplicamos la fórmula
$$ Prevalencia=\frac{-2 \cdot (Especificidad-1) \pm \sqrt{(2 \cdot (Especificidad-1))^2-4 \cdot (1-Sensibilidad-Especificidad) \cdot (1-Especificidad)}}{2 \cdot (1-Sensibilidad-Especificidad)} $$
- Vamos a simplificar la parte izquierda de dentro de la raíz cuadrada:
$$ (2 \cdot (Especificidad-1))^2=4 \cdot (Especificidad-1)^2=4 \cdot (Especificidad^2+1-2 \cdot Especificidad) $$
- Vamos a simplificar la parte derecha de dentro de la raíz cuadrada:
$$ 4 \cdot (1-Sensibilidad-Especificidad) \cdot (1-Especificidad)= $$
$$ 4 \cdot (1-Sensibilidad-Especificidad-Especificidad+Sensibilidad \cdot Especificidad+Especificidad^2)= $$ $$ 4 \cdot (1-Sensibilidad-2 \cdot Especificidad+Sensibilidad \cdot Especificidad+Especificidad^2) $$
- Y ahora vamos a unir las 2 partes de dentro de la raíz cuadrada:
$$ 4 \cdot (Especificidad^2+1-2 \cdot Especificidad)-4 \cdot (1-Sensibilidad-2 \cdot Especificidad+Sensibilidad \cdot Especificidad+Especificidad^2)= $$
$$ 4 \cdot (Especificidad^2+1-2 \cdot Especificidad-1+Sensibilidad+2 \cdot Especificidad-Sensibilidad \cdot Especificidad-Especificidad^2)= $$
$$ 4 \cdot (Sensibilidad-Sensibilidad \cdot Especificidad)=4 \cdot Sensibilidad \cdot (1-Especificidad) $$
- Ahora vamos a volver a poner la ecuación entera en la que ya hemos simplificado la parte de la raíz cuadrada.
$$ Prevalencia=\frac{-2 \cdot (Especificidad-1) \pm \sqrt{4 \cdot Sensibilidad \cdot (1-Especificidad)}}{2 \cdot (1-Sensibilidad-Especificidad)}= $$
$$ \frac{-2 \cdot (Especificidad-1) \pm 2 \cdot \sqrt{Sensibilidad \cdot (1-Especificidad)}}{2 \cdot (1-Sensibilidad-Especificidad)}= $$
$$ \frac{(1-Especificidad) \pm \sqrt{Sensibilidad \cdot (1-Especificidad)}}{1-Sensibilidad-Especificidad}= $$
- De las 2 soluciones solo nos interesa la que da un prevalencia mayor que cero así que quitamos el $\pm$ y lo dejamos en un $-$
$$ \frac{(1-Especificidad) - \sqrt{Sensibilidad \cdot (1-Especificidad)}}{1-Sensibilidad-Especificidad} $$
- Por último cambiamos todo de signo
$$ \frac{-(1-Especificidad) + \sqrt{Sensibilidad \cdot (1-Especificidad)}}{-(1-Sensibilidad-Especificidad)}= $$
$$ \frac{\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)}{Sensibilidad-(1-Especificidad)} $$
Demostrar que una fórmula es igual a la otra (Pincha para ver todo el desarrollo matemático)
$$ Prevalence \; threshold \; (PT)=\frac{\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)}{Sensibilidad-(1-Especificidad)}=\frac{\sqrt{1-Especificidad}}{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}} $$
$$ \frac{\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)}{Sensibilidad-(1-Especificidad)} \cdot \frac{1}{1}= $$
$$ \frac{\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)}{Sensibilidad-(1-Especificidad)} \cdot \frac{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}}{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}}= $$
$$ \frac{[\sqrt{Sensibilidad \cdot (1-Especificidad)}-(1-Especificidad)] \cdot (\sqrt{Sensibilidad}+\sqrt{1-Especificidad})}{[Sensibilidad-(1-Especificidad)] \cdot (\sqrt{Sensibilidad}+\sqrt{1-Especificidad})}= $$
$$ \frac{Sensibilidad \sqrt{1-Especificidad}-(1-Especificidad)\sqrt{Sensibilidad}+(1-Especificidad)\sqrt{Sensibilidad}-(1-Especificidad)\sqrt{1-Especificidad}}{Sensibilidad \sqrt{Sensibilidad}-(1-Especificidad)\sqrt{Sensibilidad}+Sensibilidad\sqrt{1-Especificidad}-(1-Especificidad)\sqrt{1-Especificidad}}= $$
$$ \frac{Sensibilidad \sqrt{1-Especificidad}-(1-Especificidad)\sqrt{Sensibilidad}+(1-Especificidad)\sqrt{Sensibilidad}-(1-Especificidad)\sqrt{1-Especificidad}}{Sensibilidad \sqrt{Sensibilidad}-(1-Especificidad)\sqrt{Sensibilidad}+Sensibilidad\sqrt{1-Especificidad}-(1-Especificidad)\sqrt{1-Especificidad}}= $$
$$ \frac{Sensibilidad \sqrt{1-Especificidad}-(1-Especificidad)\sqrt{1-Especificidad}}{Sensibilidad \sqrt{Sensibilidad}-(1-Especificidad)\sqrt{Sensibilidad}+Sensibilidad\sqrt{1-Especificidad}-(1-Especificidad)\sqrt{1-Especificidad}}= $$
$$ \frac{(Sensibilidad-(1-Especificidad)) \sqrt{1-Especificidad}}{Sensibilidad \sqrt{Sensibilidad}-(1-Especificidad)\sqrt{Sensibilidad}+Sensibilidad\sqrt{1-Especificidad}-(1-Especificidad)\sqrt{1-Especificidad}}= $$
$$ \frac{(Sensibilidad-(1-Especificidad)) \sqrt{1-Especificidad}}{Sensibilidad(\sqrt{Sensibilidad}+\sqrt{1-Especificidad})-(1-Especificidad)(\sqrt{Sensibilidad}+\sqrt{1-Especificidad})}= $$
$$ \frac{(Sensibilidad-(1-Especificidad)) \sqrt{1-Especificidad}}{[Sensibilidad-(1-Especificidad)](\sqrt{Sensibilidad}+\sqrt{1-Especificidad})}= $$
$$ \frac{\sqrt{1-Especificidad}}{\sqrt{Sensibilidad}+\sqrt{1-Especificidad}} $$
Ahora bien, ¿Que tiene de especial esa prevalencia? Pues veámoslo en cada una de las 2 gŕaficas.
- Gráfica izquierda: Antes de la prevalencia 0.09, aumentar un poquito la prevalencia, aumenta mucho la precisión, pero después de la prevalencia 0.09, aumentar un poquito la prevalencia aumenta poco la precisión.
- Gráfica izquierda:Antes de la prevalencia 0.91, aumentar un poquito la prevalencia, aumenta poco la precisión, pero después de la prevalencia 0.91, aumentar un poquito la prevalencia aumenta mucho la precisión.
Es decir que $Prevalence \; threshold \; (PT)$ es el punto en el que cambia la velocidad a la que aumenta la precisión y también podríamos decir que nuestro modelo de IA será útil desde el punto de vista de la precisión a partir de una prevalencia correspondiente a $Prevalence \; threshold \; (PT)$. La explicación formal de todo ello se encuentra en Prevalence threshold (ϕe) and the geometry of screening curves.
Y como vemos para la gráfica de la izquierda, que es una buena red neuronal, el valor de $Prevalence \; threshold \; (PT)$ es pequeño y para la gráfica de la derecha, que es una mala red neuronal, el valor de $Prevalence \; threshold \; (PT)$ es alto. Pero como nos gustan métricas cuyo valor sea alto cuanto mejor es la red, nosotros vamos a trabajar con $1-Prevalence \; threshold$
Con lo que la gráfica con la nueva métrica queda ahora así:

Es decir que para:
- $Sensibilidad=0.99 \; {\text y} \; Especificidad=0.99 \; \; \; \Rightarrow \; \; \; 1-PT=0.91$
- $Sensibilidad=0.01 \; {\text y} \; Especificidad=0.01 \; \; \; \Rightarrow \; \; \; 1-PT=0.09$
Podemos ver más ejemplos para diversas sensibilidades y especificidades en la siguiente figura:

Una característica que tiene esta métrica es que no es simétrica. No da lo mismo si intercambiamos los valores de sensibilidad y especificidad
| Sensibilidad | Especificidad | 1-PT |
|---|---|---|
| 0,90 | 0,30 | 0,53 |
| 0,30 | 0,90 | 0,63 |
| Sensibilidad | Especificidad | 1-PT |
|---|---|---|
| 0,70 | 0,50 | 0,54 |
| 0,50 | 0,70 | 0,56 |
| Sensibilidad | Especificidad | 1-PT |
|---|---|---|
| 0,90 | 0,70 | 0,63 |
| 0,70 | 0,90 | 0,73 |
ROC-AUC
La métrica ROC-AUC es el valor del area bajo la curva ROC. La palabra AUC viene de traducir "Area bajo la curva" al inglés "Area Under the Curve" o AUC. Y ROC viene del inglés "Receiver Operating Characteristic".
Vamos primero a explicar como se calcvula la curva ROC. Lo primero es que cuando predecimos que ciertos valores son Positivos o Negativos, lo hacemos en base a un umbral del resultado de la red neuronal (también llamado y_score). Normalmente si el score es menor o igual que 0.5 decimos que es Negativo y si el score es mayor que 0.5 decimos que es Positivo. Pero ese umbral es arbitrario.
La siguiente imagen muestra la distribución de valores que hemos definido como presuntamente Positivos y los presuntamente Negativos. Si superan ese umbral se convierten en Falsos Positivos o Falsos Negativos.
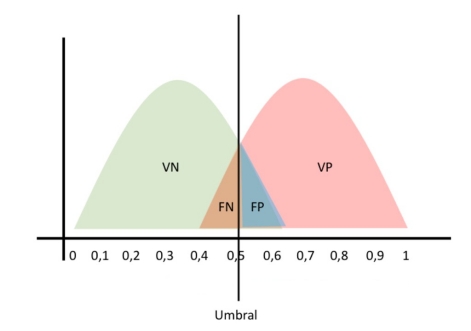
En las siguientes gráficas vamos a ver como afecta a nuestro modelo el variar el umbral.
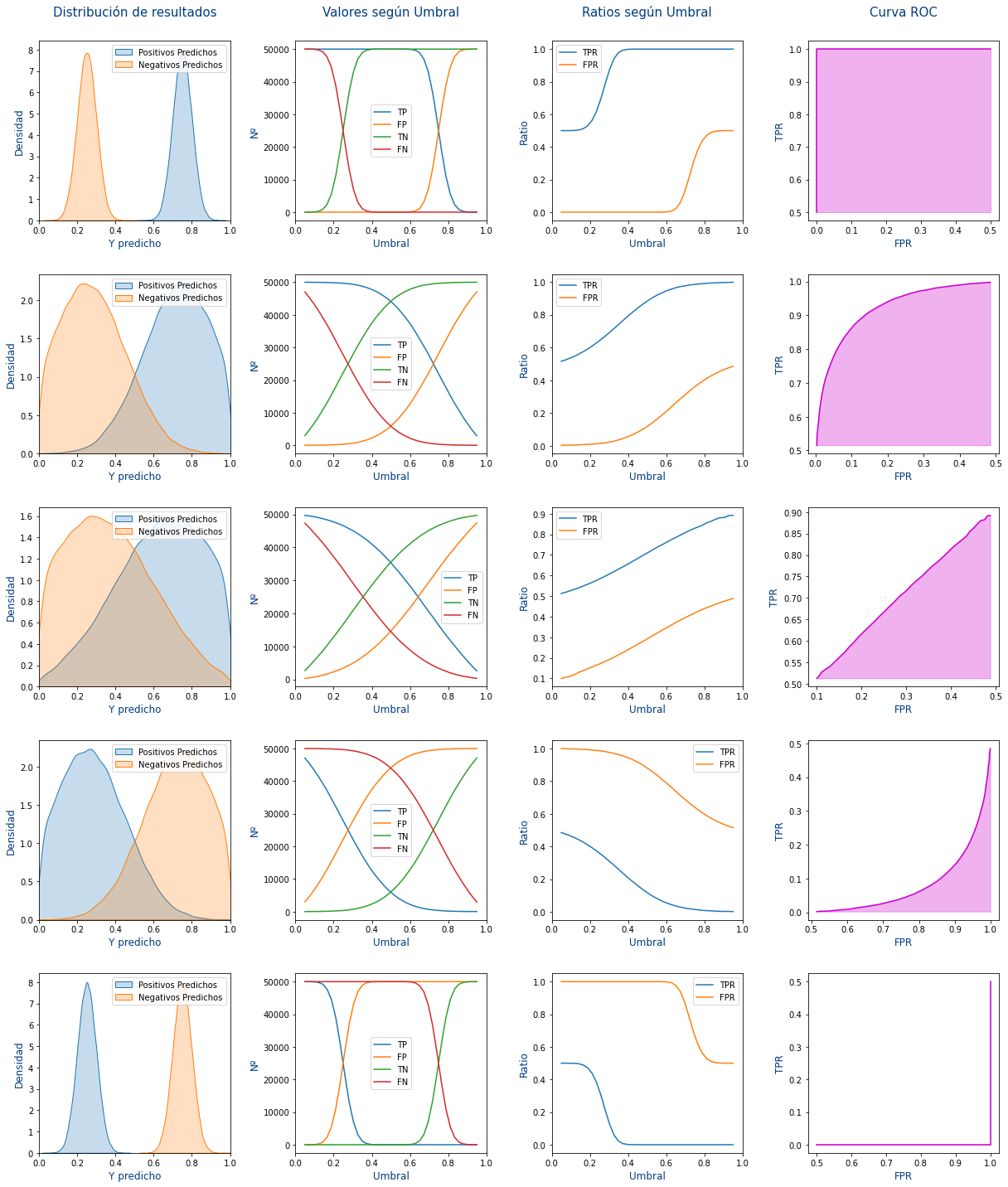
Vamos a explicar cada columna de la imagen anterior:
- 1º Columna: Se muestra la distribución de los scores Positivos y los scores Negativos que ha hecho el modelo. Pero según el umbral podrán ser True Positive (TP), True Negative (TN),False Positive (FP) y False Negative (FN)
- 2º Columna: Se muestra como evolucionan los True Positive (TP), True Negative (TN),False Positive (FP) y False Negative (FN) según se modificara el umbral. Para ello para cada umbral entre 0 y 1:
- Se cuenta cuantos Positivos hay bajo el umbral que serán los False Positive (FP)
- Se cuenta cuantos Positivos hay sobre el umbral que serán los True Positive (TP)
- Se cuenta cuantos Negativos hay bajo el umbral que serán los True Negative (TN)
- Se cuenta cuantos Negativos hay sobre el umbral que serán los False Negative (FN)
- 3º Columna: Se calculan las métricas de True Positive Rate (TPR) y False Positive Rate (FPR) según las siguientes fórmulas:
$$ \begin{array} \\ True \: Positive \: Rate \: (TPR)&=& Sensibilidad &=& \frac{TP}{TP+FN} \\ False \: Positive \: Rate \: (FPR)&=& 1-Especificidad &=& \frac{FP}{FP+TN} \end{array} $$
- 4º Columna: Muestra el True Positive Rate (TPR) frente a False Positive Rate (FPR). Es decir que cada punto la
Xde la gráfica es el FPR y laYde la gráfica es el TPR.
Cada una de las filas de la imagen son predicciones distintas, siendo:
- 1º Fila: Una predicción perfecta.
- 2º Fila: Una predicción buena
- 3º Fila: Una predicción mala en la que falla lo mismo que acierta. Sería como hacerlo aleatorio con un 50% de probabilidades de acertar.
- 4º Fila: Una predicción nefasta que falla la mayoría de las veces.
- 5º Fila: Una predicción lamentable que nunca acierta.
Entonces, ¿Que es la ROC-AUC? Es el área de la curva ROC es decir el área rosa de las gráficas de la última columna. Si nos fijamos cuanto mejor es la predicción, mayor es el área rosa y por lo tanto mayor es la métrica de ROC-AUC.
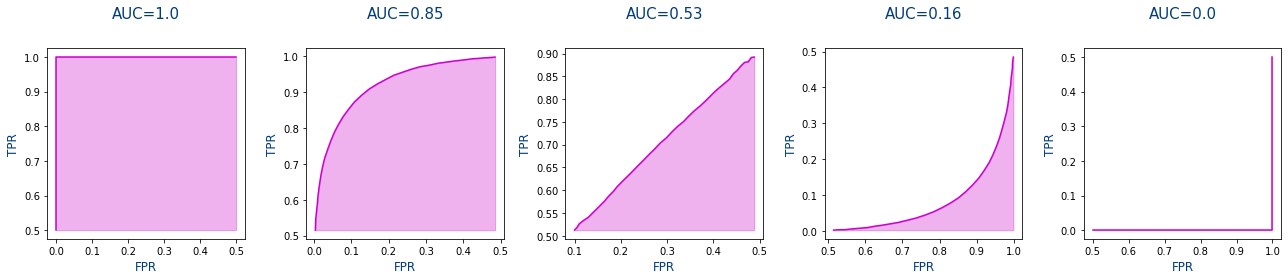
Significado de ROC-AUC
Pero ahora viene lo importante, ¿Que está midiendo el Area bajo la curva ROC o "ROC-AUC"? Pues simplemente la probabilidad de que eligiendo dos valores de entrada a la red, uno positivo y otro negativo; sea mayor el score del positivo que del negativo.
Pongamos un pequeño ejemplo: Imaginemos que tenemos una red neuronal que detecta en base a una imagen de RX de Torax si tenemos neumonía (Positivo) o si no tenemos neumonía (Negativo):
- Elegimos aleatóriamente una imagen que tiene SI neumonía y predecimos con la red neuronal si tiene o no neumonía , la red neuronal nos retornará un resultado , por ejemplo $Y_{score-true}=0,73$.
- Elegimos aleatóriamente otra imagen que tiene NO neumonía y predecimos con la red neuronal si tiene o no neumonía , la red neuronal nos retornará un resultado , por ejemplo $Y_{score-false}=0,34$.
Vemos que $Y_{score-true}>Y_{score-false}$, pero si repetimos este mismo experimentos con miles de imágenes aleatorías, pero siempre en parejas de una con neumonía (positiva) y otra sin neumonía (negativa). ¿Cual es la probabilidad de que sea mayor el valor de la positiva que el de la negativa? Es decir cual es la probabilidad de que $P(Y_{score-true}>Y_{score-false})$, o dicho de otro modo,¿cuanto vale $P(Y_{score-true}>Y_{score-false})$?
Por lo tanto:
$$ P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC $$
Vale, pero ¿Y que utilidad tiene eso? ¿Para que quiero saber $P(Y_{score-true}>Y_{score-false})$? Veámoslo con un ejemplo: Sigamos con el ejemplo de una red neuronal que detecta en base a una imagen de RX de Torax si tenemos neumonía (Positivo) o si no tenemos neumonía (Negativo).
- Ejemplo 1:
La red neuronal ha dado los siguientes resultado:
y_true=[0,0,0,1,1,1] y_score=[0.34,0.67,0.51,0.78,0.92,0.75]
| Score con neumonía=$Y_{score-true}$ | Score sin neumonía=$Y_{score-false}$ | $Y_{score-true}>Y_{score-false}$ |
|---|---|---|
| 0,78 | 0,34 | Si |
| 0,78 | 0,67 | Si |
| 0,78 | 0,51 | Si |
| 0,92 | 0,34 | Si |
| 0,92 | 0,67 | Si |
| 0,92 | 0,51 | Si |
| 0,75 | 0,34 | Si |
| 0,75 | 0,67 | Si |
| 0,75 | 0,51 | Si |
Hay un total 9 posibilidades, y en 9 de ellas se da el caso de que el Score con neumonía > Score sin neumonía. Por lo tanto:
$$ P(Score \; con \; neumonía > Score \; sin \; neumonía)=P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC=\frac {9}{9}=1 $$
- Ejemplo 2:
y_true=[0,0,0,1,1,1] y_score=[0.78,0.92,0.75,0.34,0.67,0.51]
| Score con neumonía=$Y_{score-true}$ | Score sin neumonía=$Y_{score-false}$ | $Y_{score-true}>Y_{score-false}$ |
|---|---|---|
| 0,34 | 0,78 | No |
| 0,34 | 0,92 | No |
| 0,34 | 0,75 | No |
| 0,67 | 0,78 | No |
| 0,67 | 0,92 | No |
| 0,67 | 0,75 | No |
| 0,51 | 0,78 | No |
| 0,51 | 0,92 | No |
| 0,51 | 0,75 | No |
Hay un total 9 posibilidades, y en 0 de ellas se da el caso de que el Score con neumonía > Score sin neumonía. Por lo tanto:
$$ P(Score \; con \; neumonía > Score \; sin \; neumonía)=P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC=\frac {0}{9}=0 $$
- Ejemplo 3:
y_true=[0,0,0,1,1,1] y_score=[0.4,0.6,0.3,0.7,0.2,0.8]En este caso
| Score con neumonía=$Y_{score-true}$ | Score sin neumonía=$Y_{score-false}$ | $Y_{score-true}>Y_{score-false}$ |
|---|---|---|
| 0,7 | 0,4 | Si |
| 0,7 | 0,6 | Si |
| 0,7 | 0,3 | Si |
| 0,2 | 0,4 | No |
| 0,2 | 0,6 | No |
| 0,2 | 0,3 | No |
| 0,8 | 0,4 | Si |
| 0,8 | 0,6 | Si |
| 0,8 | 0,3 | Si |
Hay un total 9 posibilidades, y en 6 de ellas se da el caso de que el Score con neumonía > Score sin neumonía. Por lo tanto:
$$ P(Score \; con \; neumonía > Score \; sin \; neumonía)=P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC=\frac {6}{9}=0,67 $$
Es decir:
- Si $P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC=1$ significa que podemos distinguir perfectamente una imagen con neumonía de otra sin neumonía, ya que hay un umbral a partir del cual podemos distinguirlo
- Si $P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC=0$ es imposible (realmente si que podemos imaginando que los resultado con neumonía son los inferiores pero imaginemos que no lo hacemos). Y no hay un umbral que permita distinguirlos
- Si $P(Y_{score-true}>Y_{score-false})=ROC\text{-}AUC=0.67$ a veces no vamos a podes distinguir si tiene neumonía o si no lo tiene.
Por todo ello nos interesa un valor lo más cercano a 1 en ROC-AUC y eso significará que la red neuronal es más capaz de distinguir lo que tienen neumonía de los que no la tienen. Y todo ello de forma independiente del umbral que elijamos.
¿Y tiene alguna otra utilidad ROC-AUC? Pues según Disadvantages of using the area under the receiver operating characteristic curve to assess imaging tests: A discussion and proposal for an alternative approach y AUC: A misleading measure of the performance of predictive distribution models no es mucho más útil. Pero como cualquier otra métrica , siempre es útil mostrarla para ver que no tenga una valor bajo ya que nos puede indicar que hay algo malo en el modelo. Por último parece que una de sus mayores utilidades es que lo pide la US Food and Drug Administration (FDA).
Pero como en las anteriores métricas que estamos viendo es una métrica que solo se basa en la sensibilidad y la especificidad.
En keras podemos usar la métrica de ROC-AUC de la siguiente forma:
metrics=[tf.keras.metrics.AUC()] metrics=["AUC"]
y usarla como
history.history['auc'] history.history['val_auc']
Con sklearn podemos usar la métrica de ROC-AUC de la siguiente forma:
from sklearn.metrics import roc_auc_score y_true = np.array([0, 0, 1, 1]) y_score = np.array([0.1, 0.4, 0.35, 0.8]) roc_auc=roc_auc_score(y_true,y_score)
Mas información:
- Mathematics behind ROC-AUC interpretation y Mathematics behind ROC-AUC interpretation.pdf: Demostración de que
ROC-AUC=P(y_score_true>Y_score_false) - Cálculo del mejor Threshold:
Accuracy
Accuracy (Exactitud) mide la proporción de predicciones correctas sobre el total de predicciones realizadas. Por lo que su fórmula es:
$$ Accuracy=\frac{TP+TN}{TP+FN+FP+TN} $$
Y también se puede expresar usando Especificidad, Sensibilidad y Prevalencia:
$$ Accuracy=Especificidad+(Sensibilidad-Especificidad) \cdot Prevalencia $$
Demostración de la fórmula usando Especificidad, Sensibilidad y Prevalencia: (Pincha para ver todo el desarrollo matemático)
$$ N=Total \; de \; predicciones=TP+FN+FP+TN $$ $$ E=Nº \; de \; enfermos=TP+FN $$ $$ S=Nº \; de \; sanos=FP+TN $$ $$ N=E+S $$ $$ Prevalencia=\frac{E}{N} \; \; \; \; \; \Rightarrow \; \; \; \; \; E=Prevalencia \cdot N $$ $$ 1-Prevalencia=\frac{S}{N} \; \; \; \; \; \Rightarrow \; \; \; \; \; S=(1-Prevalencia) \cdot N $$ $$ Sensibilidad=\frac{TP}{TP+FN}=\frac{TP}{E} \; \; \; \; \; \Rightarrow \; \; \; \; \; TP=Sensibilidad \cdot E=Sensibilidad \cdot Prevalencia \cdot N $$ $$ Especificidad=\frac{TN}{FP+TN}=\frac{TN}{E} \; \; \; \; \; \Rightarrow \; \; \; \; \; TN=Especificidad \cdot S=Especificidad \cdot (1-Prevalencia) \cdot N $$
$$ Accuracy=\frac{TP+TN}{N}=\frac{TP+TN}{E+S}= $$ $$ \frac{Sensibilidad \cdot Prevalencia \cdot N+Especificidad \cdot (1-Prevalencia) \cdot N}{Prevalencia \cdot N+(1-Prevalencia) \cdot N}= $$
$$ \frac{Sensibilidad \cdot Prevalencia+Especificidad \cdot (1-Prevalencia)}{Prevalencia+(1-Prevalencia)}= $$
$$ \frac{Sensibilidad \cdot Prevalencia+Especificidad \cdot (1-Prevalencia)}{Prevalencia-Prevalencia+1}= $$
$$ Sensibilidad \cdot Prevalencia+Especificidad \cdot (1-Prevalencia)= $$
$$ Sensibilidad \cdot Prevalencia+Especificidad-Especificidad \cdot Prevalencia= $$
$$ Accuracy=Especificidad+(Sensibilidad-Especificidad) \cdot Prevalencia $$
Esta métrica es la más sencilla de todas ya que simplemente es el "porcentaje" de cuantas veces acierta en función de todas las predicciones que ha hecho.
Como ya hemos comentado, lo bueno que es intrínsecamente nuestro modelo se defiende por las métricas de sensibilidad y especificidad. Sin embargo, la prevalencia modifica el resultado final y es con lo que se calcula el VPP y VPN. Pues bien, lo que queremos es tener un número (en este caso la métrica de Accuracy) y que nos diga cómo es de buena nuestra red neuronal bajo las distintas prevalencias, sensibilidades y especificidades.
En la siguiente figura vemos como se comparta bajo distintos valores de sensibilidad, especificidad y prevalencia.

Si nos fijamos en cada una de las gráficas, vemos que siempre es una linea recta. Mirando también en la fórmula podemos verlo como una ecuación de primer grado que depende de la prevalencia. El valor de accuracy es una línea recta desde la especificidad hasta la sensibilidad. ¿Es un buen resumen de nuestra red? Pues si tenemos baja prevalencia, la accuracy prácticamente es la especificidad y con alta prevalencia, la accuracy es prácticamente la sensibilidad. Pues no parece que sea muy buena resumiendo los valores de sensibilidad y especificidad bajo distintas prevalencias.
Pero veamos los siguientes ejemplo de matrices de confusión para ver lo poco representativo que es esta métrica:

Matthews Correlation Coefficient (MCC)
El $Matthews \; Correlation \; Coefficient \; (MCC)$ es simplemente el Coeficiente de correlación de Pearson para una muestra. Es decir es un coficiente que nos dice como de similares son dos variables aleatorias. En este caso las 2 variable aleatorias son los valores verdaderos y_true y los valores predichos y_pred
Su fórmula es:
$$ MCC=\frac{TN \cdot TP-FN \cdot FP}{\sqrt{ (TP+FN)(FP+TN) \cdot (FN+TN)(TP+FP)}} $$
Demostración de la fórmula: La fórmula del Coeficiente de correlación de Pearson para una muestra. (Pincha para ver todo el desarrollo matemático)
$$ Coeficiente \; de \; correlación \; de \; Pearson \; para \; una \; muestra=\frac{\sum (x_i-\overline{x})(y_i-\overline{y})}{\sqrt{\sum (x_i-\overline{x})^2}\sqrt{\sum (y_i-\overline{y})^2}} $$
Pero se puede simplificar la formula a (véase todos los pasos en Sumatorios)
$$ Coeficiente \; de \; correlación \; de \; Pearson \; para \; una \; muestra=\frac{ \sum (x_i y_i) - n \cdot \overline{x} \cdot \overline{y}}{ \sqrt{\sum x_i^2 - n \cdot \overline{x}^2 }\sqrt{\sum y_i^2 - n \cdot \overline{y}^2} } $$
Pero para crear en MMC:
- $x_i$: La lista de los valores verdaderos. Que sabemos que valen 0 o 1
- $y_i$: La lista de los valores predichos. Que sabemos que valen 0 o 1
Por lo tanto: $$ n=TP+FN+FP+TN $$ $$ \sum (x_i y_i)=TP $$ $$ \sum x_i^2=Nº \; Enfermos=TP+FN $$ $$ \sum y_i^2=Nº \; Predichos \; positivos=TP+FP $$ $$ \overline{x}=\frac{Nº \; Enfermos}{n}=\frac{TP+FN}{n}=\frac{TP+FN}{TP+FN+FP+TN} $$ $$ \overline{y}=\frac{Nº \; Predichos \; positivos}{n}=\frac{TP+FP}{n}=\frac{TP+FP}{TP+FN+FP+TN} $$
- Y subtituyendo:
$$ \frac{ \sum (x_i y_i) - n \cdot \overline{x} \cdot \overline{y}}{ \sqrt{\sum x_i^2 - n \cdot \overline{x}^2 }\sqrt{\sum y_i^2 - n \cdot \overline{y}^2} }= $$
$$ \frac{TP-n(\frac{TP+FN}{n})(\frac{TP+FP}{n})}{\sqrt{(TP+FN)-n(\frac{(TP+FN)^2}{n^2})}\sqrt{(TP+FP)-n(\frac{(TP+FP)^2}{n^2})}}= $$
$$ \frac{\frac{n^2TP}{n^2}-\frac{n(TP+FN)(TP+FP)}{n^2}}{\sqrt{\frac{n^2(TP+FN)}{n^2}-\frac{n(TP+FN)^2}{n^2}}\sqrt{\frac{n^2(TP+FP)}{n^2}-\frac{n(TP+FP)^2}{n^2}}}= $$
$$ \frac{\frac{n^2TP-n(TP+FN)(TP+FP)}{n^2}}{\frac{\sqrt{n^2(TP+FN)-n(TP+FN)^2}}{\sqrt{n^2}}\frac{\sqrt{n^2(TP+FP)-n(TP+FP)^2}}{\sqrt{n^2}}}= $$
$$ \frac{\frac{n^2TP-n(TP+FN)(TP+FP)}{n^2}}{\frac{\sqrt{n^2(TP+FN)-n(TP+FN)^2}}{n}\frac{\sqrt{n^2(TP+FP)-n(TP+FP)^2}}{n}}= $$
$$ \frac{\frac{n^2TP-n(TP+FN)(TP+FP)}{n^2}}{\frac{\sqrt{n^2(TP+FN)-n(TP+FN)^2} \cdot \sqrt{n^2(TP+FP)-n(TP+FP)^2}}{n^2}}= $$
$$ \frac{n^2TP-n(TP+FN)(TP+FP)}{\sqrt{n^2(TP+FN)-n(TP+FN)^2}\sqrt{n^2(TP+FP)-n(TP+FP)^2}}= $$
$$ \frac{n \cdot (nTP-(TP+FN)(TP+FP))}{\sqrt{n^2 \cdot (n(TP+FN)-(TP+FN)^2) \cdot (n(TP+FP)-(TP+FP)^2)}}= $$
$$ \frac{n \cdot (nTP-(TP+FN)(TP+FP))}{n \cdot \sqrt{(n(TP+FN)-(TP+FN)^2) \cdot (n(TP+FP)-(TP+FP)^2)}}= $$
$$ \frac{nTP-(TP+FN)(TP+FP)}{\sqrt{(n(TP+FN)-(TP+FN)^2) \cdot (n(TP+FP)-(TP+FP)^2)}} $$
- Ahora vamos a desarrollar y simplificar únicamente el numerador:
$$ nTP-(TP+FN)(TP+FP)= $$
$$ (TP+FN+FP+TN)TP-(TP+FN)(TP+FP)= $$
$$ TP \cdot TP+FN \cdot TP+FP \cdot TP+TN \cdot TP-TP \cdot TP-FN \cdot TP-TP \cdot FP-FN \cdot FP= $$
$$ TN \cdot TP-FN \cdot FP $$
- Pasemos ahora a desarrollando y simplificar la parte izquierda del denominador
$$ n(TP+FN)-(TP+FN)^2= $$
$$ (TP+FN+FP+TN)(TP+FN)-(TP+FN)^2= $$
$$ TP \cdot TP + FN \cdot TP+ FP \cdot TP+ TN \cdot TP + \\ TP \cdot FN + FN \cdot FN + FP \cdot FN + TN \cdot FN - \\ TP \cdot TP-FN \cdot FN-TP \cdot FN-TP \cdot FN= $$
$$ FP \cdot TP+ TN \cdot TP + FP \cdot FN + TN \cdot FN = $$
$$ TP(FP+TN)+FN(FP+TN)= $$
$$ (FP+TN)(TP+FN) $$
- Y por último la parte derecha del denominador
$$ n(TP+FP)-(TP+FP)^2= $$
$$ (TP+FN+FP+TN)(TP+FP)-(TP+FP)^2= $$
$$ TP \cdot TP + FN \cdot TP + FP \cdot TP + TN \cdot TP + \\ TP \cdot FP + FN \cdot FP + FP \cdot FP + TN \cdot FP - \\ TP \cdot TP-FP \cdot FP-TP \cdot FP-TP \cdot FP= $$
$$ FN \cdot TP + TN \cdot TP + FN \cdot FP + TN \cdot FP= $$
$$ TP(FN+TN)+FP(FN+TN)= $$
$$ (FN+TN)(TP+FP) $$
- Y juntando las 3 partes (numerador, izquierda denominador y derecha denominador) se obtiene ya fórmula exacta del MCC
$$ \frac{nTP-(TP+FN)(TP+FP)}{\sqrt{(n(TP+FN)-(TP+FN)^2) \cdot (n(TP+FP)-(TP+FP)^2)}}= $$
$$ \frac{TN \cdot TP-FN \cdot FP}{\sqrt{ (FP+TN)(TP+FN) \cdot (FN+TN)(TP+FP)}}=MCC $$
La formula según la prevalencia es:
$$ MCC=\frac{Sensibilidad+Especificidad-1}{\sqrt{ \frac{Prevalencia}{1-Prevalencia} Sensibilidad - Especificidad +1} \cdot \sqrt{ \frac{1-Prevalencia}{Prevalencia} Especificidad - Sensibilidad +1}} $$
Demostración fórmula en función Sensibilidad , Especificidad y Prevalencia (Pincha para ver todo el desarrollo matemático)
$$ MCC=\frac{Sensibilidad+Especificidad-1}{\sqrt{ \frac{Prevalencia}{1-Prevalencia} Sensibilidad - Especificidad +1} \cdot \sqrt{ \frac{1-Prevalencia}{Prevalencia} Especificidad - Sensibilidad +1}} $$
- Para simplificar la demostración para a hacer los siguientes cambios de variables y simplificaciones:
$$ \\ E=Enfermos=TP+FN \\ S=Sanos=FP+TN \\ Prevalencia=\frac{Enfermos}{Enfermos+Sanos}=\frac{E}{E+S} \\ 1-Prevalencia=\frac{Sanos}{Enfermos+Sanos}=\frac{S}{E+S} \\ \frac{Prevalencia}{1-Prevalencia}=\frac{E}{E+S} : \frac{S}{E+S}=\frac{E}{S} \\ \frac{1-Prevalencia}{Prevalencia}=\frac{S}{E+S} : \frac{E}{E+S} =\frac{S}{E} $$
- Ahora vamos a desarrollar y simplificar únicamente el numerador:
$$ Sensibilidad+Especificidad-1=\frac{TP}{E}+\frac{TN}{S}-1= $$
$$ \frac{S \cdot TP}{E \cdot S}+\frac{E \cdot TN}{E \cdot S}-\frac{E \cdot S}{E \cdot S}= $$
$$ \frac{S \cdot TP + E \cdot TN - E \cdot S}{E \cdot S}= $$
$$ \frac{TP(FP+TN) + TN(TP+FN) - (TP+FN)(FP+TN) }{E \cdot S}= $$
$$ \frac{TP \cdot FP \; + \; TP \cdot TN \; + \; TN \cdot TP \; + \; TN \cdot FN \; - \; TP \cdot FP \; - \; TP \cdot TN \; - \; FN \cdot FP \; - \; FN \cdot TN}{E \cdot S}= $$
$$ \frac{TP \cdot TN \; - \; FN \cdot FP}{E \cdot S}= $$
- Pasemos ahora a desarrollando y simplificar el contenido de la raíz izquierda del denominador.
$$ \frac{Prevalencia}{1-Prevalencia} Sensibilidad - Especificidad +1= $$
$$ \frac{E}{S} \cdot \frac{TP}{E}-\frac{TN}{S}+1= $$ $$ \frac{TP}{S}-\frac{TN}{S}+\frac{S}{S}=\frac{TP}{S}-\frac{TN}{S}+\frac{FP+TN}{S}= $$
$$ \frac{TP-TN+FP+TN}{S}=\frac{TP+FP}{S}=\frac{E \cdot (TP+FP)}{E \cdot S}= $$
$$ \frac{(TP+FN) \cdot (TP+FP)}{E \cdot S}= $$
- Pasemos ahora a desarrollando y simplificar el contenido de la raíz derecha del denominador.
$$ \frac{1-Prevalencia}{Prevalencia} Especificidad - Sensibilidad +1 $$
$$ \frac{S}{E} \cdot \frac{TN}{S}-\frac{TP}{E}+1= $$
$$ \frac{TN}{E}-\frac{TP}{E}+\frac{E}{E}=\frac{TN}{E}-\frac{TP}{E}+\frac{TP+FN}{E}= $$
$$ \frac{TN-TP+TP+FN}{E}=\frac{TN+FN}{E}=\frac{S \cdot (TN+FN)}{E \cdot S} $$
$$ \frac{(FP+TN) \cdot (TN+FN)}{E \cdot S}= $$
- Y juntando las 3 partes (numerador, contenido raíz izquierda denominador y contenido raíz derecha denominador) se obtiene:
$$ \frac{\frac{TP \cdot TN \; - \; FN \cdot FP}{E \cdot S}}{\sqrt{ \frac{(TP+FN) \cdot (TP+FP)}{E \cdot S}} \cdot \sqrt{ \frac{(FP+TN) \cdot (TN+FN)}{E \cdot S}}}= $$
$$ \frac{TN \cdot TP \; - \; FN \cdot FP}{\sqrt{ (TP+FN)(FP+TN) \cdot (FN+TN)(TP+FP) }}=MCC $$
El MMC tiene un valor entre -1 a 1. Siendo:
- $1$ : El clasificador funciona perfectamente y es cuando hay una completa correlación entre lo predicho y lo verdadero.
- $0$ : El clasificador acierta aleatoriamente y es cuando hay una nula correlación entre lo predicho y lo verdadero.
- $-1$ : El clasificador acierta peor que aleatoriamente, es decir que clasifica al revés "perfectamente" y es cuando hay correlación inversa entre lo predicho y lo verdadero.
En la siguiente imagen podemos ver distintos valores del Coeficiente de correlación de Pearson:

Es decir que el MMC solo mide la relación lineal entre los valores verdaderos y_true y los valores predichos y_pred.
- Si esa relación es lineal directa, el MMC valdrá 1
- Si no hay una relación lineal, el MMC valdrá 0
- Si la relación es lineal inversa, el MMC valdrá -1.
Como en otro casos, al ser el MMC un valor de -1 a 1, lo vamos a normalizar para que su valor sea de 0 a 1 y de esa forma sea más sencillo de comparar con otras métricas. A esta nueva métrica la llamaremos $MMC \; normalizado$ o $nMMC$
$$ MMC \; normalizado=nMMC=\frac{MMC+1}{2} $$
Veamos en la siguiente figura los mismos ejemplos que en $Accuracy$ y los vamos a comparar

Podemos hacer uso de la métrica con la función sklearn.metrics.matthews_corrcoef de sklearn
Ejemplo de uso:
from sklearn.metrics import matthews_corrcoef
y_true = [1,1,1,1,0,0,0,0]
y_pred = [1,1,1,1,0,0,0,0]
print("Valor para una predicción que acierta siempre =",matthews_corrcoef(y_true,y_pred))
y_true = [1,1,1,1,0,0,0,0]
y_pred = [1,1,0,0,1,1,0,0]
print("Valor para una predicción que acierta la mitad=",matthews_corrcoef(y_true,y_pred))
y_true = [1,1,1,1,0,0,0,0]
y_pred = [0,0,0,0,1,1,1,1]
print("Valor para una predicción que nunca acierta =",matthews_corrcoef(y_true,y_pred))
Valor para una predicción que acierta siempre = 1.0 Valor para una predicción que acierta la mitad= 0.0 Valor para una predicción que nunca acierta = -1.0
y por último vamos a hacer una prueba si el MCC y el Coeficiente de correlación de Pearson dan el mismo resultado.
import numpy as np
import tensorflow
from sklearn.metrics import matthews_corrcoef
from scipy.stats import pearsonr
np.random.seed(7)
y_true=np.random.choice([0, 1], size=500000)
y_pred=np.random.choice([0, 1], size=500000)
mcc=matthews_corrcoef(y_true, y_pred)
pearson,_=pearsonr(y_true, y_pred)
print(f"MCC :{mcc:.15f}")
print(f"Pearson:{pearson:.15f}")
Y podemos comprobar que ambas métricas dan el mismo resultado.
MCC :0.002464054120502 Pearson:0.002464054120502
Mas información:
Markedness
Este índice pretende resumir los valores del VPP (precisión) y VPN. Su fórmula es:
$$ Markedness=VPP+VPN-1 $$
Como vemos, es la suma de la precisión más la VPN menos 1. Eso hace que su rango sea de -1 a 1. En estos caso como ya hemos comentado en ese caso calcularemos el $Markedness \; normalizado$ o $nMarkedness$ para que tenga un valor de 0 a 1
$$ Markedness \; Normalizado=nMarkedness=\frac{Markedness+1}{2}=\frac{VPP+VPN}{2} $$
Es decir que el $nMarkedness$ es simplemente la media aritmética de VPP y VPN. Este índice será útil si sabemos la prevalencia y los datos están más o menos balanceados.
Explicar que es lo que mide, es sencillo ya que es la media aritmética entre VPP y VPN.
Veamos en la siguiente figura los mismos ejemplos que en $Accuracy$ y los vamos a comparar

Para terminar vamos a comparar $nMCC$ y $nMarkedness$

Jaccard
El índice Jaccard es simplemente el porcentaje de TP respecto a los TP,FP y FN. Pero en vez de ser un porcentaje de 0 a 100 va de 0 a 1.
$$ Indice \; Jaccard=\frac{TP}{TP+FP+FN} $$
Demostración de la fórmula: La formula realmente se define como un cociente de probabilidades: (Pincha para ver todo el desarrollo matemático)
$$ Indice \; Jaccard=\frac{P(Positivo \cap Enfermo)}{P(Positivo \cup Enfermo)}= $$
$$ \frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo \cap Enfermo)}=\frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo|Enfermo) \cdot P(Enfermo)} $$
- Sabiendo que:
$$ \begin{array} \\ P(Enfermo)&=&\frac{TP+FN}{TP+FN+FP+TN} \\ P(Sano)&=&\frac{FP+TN}{TP+FN+FP+TN} \\ P(Positivo)&=&\frac{TP+FP}{TP+FN+FP+TN} \\ P(Negativo)&=&\frac{FN+TN}{TP+FN+FP+TN} \\ P(Positivo|Enfermo)&=&\frac{TP}{TP+FN} \end{array} $$
- Entonces:
$$ \frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo|Enfermo) \cdot P(Enfermo)}= $$
$$ \left ( \frac{TP}{TP+FN} \cdot \frac{TP+FN}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP}{TP+FN+FP+TN}+\frac{TP+FN}{TP+FN+FP+TN}-\frac{TP}{TP+FN} \cdot \frac{TP+FN}{TP+FN+FP+TN} \right )= $$
$$ \left ( \frac{TP}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP}{TP+FN+FP+TN}+\frac{TP+FN}{TP+FN+FP+TN}-\frac{TP}{TP+FN+FP+TN} \right )= $$
$$ \left ( \frac{TP}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP+TP+FN-TP}{TP+FN+FP+TN} \right )=\left ( \frac{TP}{TP+FN+FP+TN} \right ) \div \left (\frac{TP+FP+FN}{TP+FN+FP+TN} \right )= $$
$$ \frac{TP}{TP+FP+FN}=Indice \; Jaccard $$
La fórmula también se puede expresar usando a $Sensibilidad$ y la $Precision$
$$ Indice \; Jaccard=\frac{Precision \cdot Sensibilidad}{Precision+Sensibilidad-Precision \cdot Sensibilidad} $$
Demostración fórmula en función $Sensibilida$ y $Precision$ (Pincha para ver todo el desarrollo matemático)
- Sabemos que:
$$ Sensibilidad=\frac{TP}{TP+FN} $$
$$ Precision=\frac{TP}{TP+FP} $$
- Despejando $FN$ y $FP$ se obtiene:
$$ FN=TP \cdot \frac{1-Sensibilidad}{Sensibilidad} $$
$$ FP=TP \cdot \frac{1-Precision}{Precision} $$
- Ahora substituyendo $FN$ y $FP$ en el índice Jacard se obtiene
$$ Indice \; Jaccard=\frac{TP}{TP+FP+FN} $$
$$ =\frac{TP}{TP+TP \cdot \frac{1-Precision}{Precision}+TP \cdot \frac{1-Sensibilidad}{Sensibilidad}} $$
$$ =\frac{1}{1+\frac{1-Precision}{Precision}+\frac{1-Sensibilidad}{Sensibilidad}} $$
$$ =\frac{1}{\frac{Precision \cdot Sensibilidad+Sensibilidad \cdot (1-Precision)+Precision \cdot (1-Sensibilidad)}{Precision \cdot Sensibilidad}} $$
$$ =\frac{Precision \cdot Sensibilidad}{Precision \cdot Sensibilidad+Sensibilidad \cdot (1-Precision)+Precision \cdot (1-Sensibilidad)} $$
$$ =\frac{Precision \cdot Sensibilidad}{Precision \cdot Sensibilidad+Sensibilidad- Sensibilidad \cdot Precision+Precision-Precision \cdot Sensibilidad} $$
$$ Indice \; Jaccard=\frac{Precision \cdot Sensibilidad}{Precision+Sensibilidad-Precision \cdot Sensibilidad} $$
Por último se puede expresar en función de $Sensibilidad$ , $Especificidad$ y $Prevalencia$:
$$ Indice \; Jaccard=\frac{Sensibilidad \cdot Prevalencia}{(1-Especificidad) \cdot (1-Prevalencia)+Prevalencia} $$
Demostración fórmula en función Sensibilidad , Especificidad y Prevalencia (Pincha para ver todo el desarrollo matemático)
- Usando el teorema de bayes podemos definir P(Positivo) de la siguiente forma:
$$ P(Positivo)=\frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{P(Enfermo|Positivo)}= $$
$$ \frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{1} \div \frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{P(Positivo|Enfermo) \cdot P(Enfermo)+P(Positivo|Sano)*P(Sano)}= $$
$$ Sensibilidad \cdot Prevalencia+(1-Especificidad) \cdot (1-Prevalencia) $$
- Y ahora usamos la formula de P(Positivo) en la definición del Indice Jaccard
$$ Indice \; Jaccard=\frac{P(Positivo|Enfermo) \cdot P(Enfermo)}{P(Positivo)+P(Enfermo)-P(Positivo|Enfermo) \cdot P(Enfermo)}= $$
$$ \frac{Sensibilidad \cdot Prevalencia}{Sensibilidad \cdot Prevalencia+(1-Especificidad) \cdot (1-Prevalencia)+Prevalencia-Sensibilidad \cdot Prevalencia}= $$
$$ \frac{Sensibilidad \cdot Prevalencia}{(1-Especificidad) \cdot (1-Prevalencia)+Prevalencia} $$
- Por lo tanto
$$ Indice \; Jaccard=\frac{Sensibilidad \cdot Prevalencia}{(1-Especificidad) \cdot (1-Prevalencia)+Prevalencia} $$
F1-score
La métrica del $F_1{\text -}score$ se suele explicar inicialmente como la media armónica entre Sensibilidad y Precision y cuya ventaja es que la media es menor que la aritmética si los valores son distintos.
- La formula con la media armónica es la siguiente:
$$F_1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}$$
- La fórmula se puede simplificar:
$$F_1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}= \frac{2}{\frac{Precision}{Sensibilidad \cdot Precision}+\frac{Sensibilidad}{Precision \cdot Sensibilidad}}=$$ $$=\frac{2}{\frac{Precision+Sensibilidad}{Sensibilidad \cdot Precision}} = \frac{2}{1}: \frac{Precision+Sensibilidad}{Sensibilidad \cdot Precision} = $$ $$F_1{\text -}score=\frac { 2 \cdot Sensibilidad \cdot Precision}{Sensibilidad + Precision}$$
- En función de la matriz de confusión se puede expresar como:
$$F_1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}=\frac{2}{\frac{1}{\frac{TP}{TP+FN}}+\frac{1}{\frac{TP}{TP+FP}}}=$$ $$=\frac{2}{\frac{TP+FN}{TP}+\frac{TP+FP}{TP}}=\frac{2}{\frac{TP+FN}{TP}+\frac{TP+FP}{TP}}=\frac{2}{\frac{TP+FN+TP+FP}{TP}}=$$ $$=\frac{2}{1}:\frac{TP+FN+TP+FP}{TP}=\frac{2 \cdot TP}{TP+FN+TP+FP}=$$ $$F_1{\text -}score=\frac{TP}{\frac{(TP+FP)+(TP+FN)}{2}}$$
- Por último de puede definir en función de la Sensibilidad, Especifidad y Prevalencia:
$$F_1{\text -}score=\frac{2*Sensibilidad*Prevalencia}{Prevalencia*(Sensibilidad+Especificidad)+(1-Especificidad)}$$
Origen de la fórmula del f1-score: (Pincha para ver todo el desarrollo matemático)
La primera vez que se habló del $F_1{\text -}score$ fue en el libro Van Rijsbergen, C. J. (1979). Information Retrieval.Chapter 7.Evaluation. En él no se define el $F_1{\text -}score$ sino su valor opuesto llamado $E$ y lo define según la teoría de conjuntos.
$$ E=1-F_1{\text -}score $$
$$ E=\frac{|Positivos \; \Delta \; Enfermos|}{|Positivos|+|Enfermos|}=\frac{|Positivos \cup Enfermos|-|Positivos \cap Enfermos|}{|Positivos|+|Enfermos|} $$
$$ F_1{\text -}score=1-E=1-\frac{|Positivos \cup Enfermos|-|Positivos \cap Enfermos|}{|Positivos|+|Enfermos|}= $$
$$ \frac{|Positivos|+|Enfermos|}{|Positivos|+|Enfermos|}-\frac{|Positivos \cup Enfermos|-|Positivos \cap Enfermos|}{|Positivos|+|Enfermos|}= $$
$$ \frac{(|Positivos|+|Enfermos|-|Positivos \cup Enfermos|)+|Positivos \cap Enfermos|}{|Positivos|+|Enfermos|}= $$
- Sabiendo que $P(A \cap B)=P(A)+P(B)-P(A \cup B)$ (véase Teoría de Probabilidad)
$$ \frac{|Positivos \cap Enfermos|+|Positivos \cap Enfermos|}{|Positivos|+|Enfermos|}= $$
$$ \frac{2 \cdot |Positivos \cap Enfermos|}{|Positivos|+|Enfermos|}=\frac{|Positivos \cap Enfermos|}{\frac{|Positivos|+|Enfermos|}{2}} $$
- Sabiendo que
$$ \begin{array} \\ |Positivos \cap Enfermos|&=&\text{Nº de enfermos y positivos}&=&TP \\ |Positivos|&=&\text{Nº positivos}&=&TP+FP \\ |Enfermos|&=&\text{Nº de enfermos}&=&TP+FN \\ \\ {\Large \frac{|Positivos \cap Enfermos|}{\frac{|Positivos|+|Enfermos|}{2}}}&=&{\Large \frac{\text{Nº de enfermos y positivos}}{\frac{\text{Nº positivos}+\text{Nº de enfermos}}{2}}}&=&{\Large \frac{TP}{\frac{(TP+FP)+(TP+FN)}{2}}} \end{array} $$
$$ F1\text{-}score=\frac{TP}{\frac{(TP+FP)+(TP+FN)}{2}} $$
Vamos ahora a explicar la fórmula según la teoría de conjuntos:
$$ \frac{|Positivos \cap Enfermos|}{\frac{|Positivos|+|Enfermos|}{2}} $$

El conjunto de los positivos son aquellos que el modelo de IA ha predicho que son positivos, mientras que el conjunto de los enfermos son los que realmente están enfermos. Si pensamos un poco nos gustaría que ambos conjuntos fueran iguales, es decir si decimos que un paciente el positivo que también esté enfermo pero si está enfermo que también sea positivo.
Veamos ahora los datos de los 3 casos de una forma numérica.
| Caso | Nº Enfermos | Nº Positivos | Nº Enfermos y Nº Positivos=TP |
|---|---|---|---|
| A | 10 | 10 | 3 |
| B | 10 | 10 | 0 |
| C | 10 | 10 | 10 |
¿que caso es mejor? Realmente el Caso C en que ambos conjuntos son iguales. El peor de los casos será el Caso B, en el que no hay ningún elemento en común , mientras que un caso intermedio es el Caso A, en el que 3 pacientes que son positivos y enfermos.
¿Y que hace la división? Simplemente normalizar el valor para que de un resultado de 0 a 1. Y ese factor por el que se divide es la media del tamaño de ambos conjuntos. Por eso en formula el denominador es la media aritmética entre el tamaño del conjunto de los enfermos (Nº de enfermos) y el tamaño del conjunto de los positivos (Nº de positivos). Y por eso me parece un error cuando ese 2 se coloca arriba multiplicando a $TP$ porque no deja claro el significado de la fórmula.
Por lo tanto, el $F_1{\text -}score$ nos está diciendo simplemente como de parecidos son el conjunto de los positivos y de los enfermos. Si el $F_1{\text -}score$ vale 1 significa que ambos conjuntos son iguales por lo que siempre que el modelo de IA diga que un paciente es positivo estará también enfermo, mientras que si $F_1{\text -}score$ vale 0 es que son totalmente distintos los conjuntos. Por lo que cuando el modelo de IA diga que un paciente es positivo nunca estará enfermo.
Para terminar, esta métrica se está centrando únicamente en los positivos y enfermos. Por lo que no nos será útil si nos interesa los sanos/negativos. Y por ello el $F_1{\text -}score$ no es una buena métrica si queremos ver el rendimiento global de nuestra IA.
Volvamos a la media armónica, ¿tiene algún tipo de importancia que en la fórmula se esté usando la media armónica? y ¿que se insista en que dicha medía da un valor inferior a la aritmética cuando los valores de sensibilidad y precisión son distintos? La respuesta a ambas preguntas es que NO.
Demostración fórmula en función Sensibilidad , Especificidad y Prevalencia (Pincha para ver todo el desarrollo matemático)
$$F_1{\text -}score=\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{Precision}}=$$ $$\frac{2}{\frac{1}{Sensibilidad}+\frac{1}{\frac{Sensibilidad*Prevalencia}{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}}}=$$ $$\frac{2}{\frac{1}{Sensibilidad}+{\frac{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2}{\frac{1}{\frac{Sensibilidad*Prevalencia}{Prevalencia}}+{\frac{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2}{{\frac{Prevalencia}{Sensibilidad*Prevalencia}}+{\frac{Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2}{{\frac{Prevalencia+Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}{Sensibilidad*Prevalencia}}}=$$ $$\frac{2*Sensibilidad*Prevalencia}{Prevalencia+Sensibilidad*Prevalencia+(1-Especificidad)*(1-Prevalencia)}=$$ $$\frac{2*Sensibilidad*Prevalencia}{Prevalencia+Sensibilidad*Prevalencia+1-Prevalencia-Especificidad+Especificidad*Prevalencia}=$$ $$\frac{2*Sensibilidad*Prevalencia}{Prevalencia*(1+Sensibilidad-1+Especificidad)+1-Especificidad}=$$ $$F_1{\text -}score=\frac{2*Sensibilidad*Prevalencia}{Prevalencia*(Sensibilidad+Especificidad)+(1-Especificidad)}$$
Más informnación:
Fowlkes-Mallows (FM)
Es la media geométrica entre la sensibilidad y la precisión
$$ Fowlkes-Mallows=\sqrt{Sensibilidad*Precisión} $$
$$ Fowlkes-Mallows=\sqrt{\frac{TP}{TP+FN}*\frac{TP}{TP+FP}}=\sqrt{\frac{TP^2}{(TP+FN)*(TP+FP)}}=\frac{TP}{\sqrt{(TP+FN)*(TP+FP)}} $$
Más información:
PR-AUC
La métrica PR-AUC es el Area bajo la curva Precisión-Especificidad (llamada en inglés Precision-Recall o PR) que se usa cuando los datos tienen una baja prevalencia. La forma de calcularlo es similar al ROC-AUC pero en vez de usar la $Sensibilidad$ y $1-Especificidad$, se calcula usando las métricas de:
$$ \begin{array} \\ Sensibilidad &=& \frac{TP}{TP+FN} &=& TPR &=& Recall \\ Precisión &=& \frac{TP}{TP+FP} &=& VPP &=& \end{array} $$
Pero sigue la misma idea de calcular esas 2 métricas para cada valor del umbral y enfrentarla una contra otra.

A esta métrica también se le llama $Preción \; media$ ya que realmente está calculado la media de las precisiones para todos los umbrales.
El métrica de ROC-AUC no tenía en cuenta la prevalencia ya que no se usaba en la fórmula. Por otro lado PR-AUC, si que tiene en cuenta la prevalencia ya que usa la precisión pero por otro lado no tiene en cuenta los $TN$. Lo que la hace válida como métrica para datos desbalanceados.
Con sklearn podemos usar la métrica de PR-AUC de la siguiente forma:
from sklearn.metrics import average_precision_score y_true = np.array([0, 0, 1, 1]) y_score = np.array([0.1, 0.4, 0.35, 0.8]) pr_auc = average_precision_score(y_true, y_score)
Más información:
Ejercicios
Ejercicio 1.A
Tenemos el modelo del tema anterior que guardaste a disco.
Carga ese modelo y usando los datos de test, calcula las métricas independientes de la prevalencia
- Informedness Normalizado
- Balanced Accuracy
- 1-Prevalence threshold (PT)
- ROC-AUC
Crea la función informedness_normalizado,balanced_accuracy,prevalence_threshold,roc_auc=get_metrics_independientes_prevalencia(y_true, y_score,threshold = 0.5)
Métrica Valor ------------------------ -------- Informedness Normalizado 0.892304 Balanced Accuracy 0.892304 1-Prevalence Threshold 0.719498 ROC-AUC 0.924796
Ejercicio 1.B
Usando los datos de test, calcula ahora las métricas de rendimiento global
- Accuracy
- Matthews correlation coefficient Normalizado (nMCC)
- Markedness
La prevalencia a usar será la de los datos.
Crea la función accuracy,mcc_normalizado,markedness=get_metrics_rendimiento_global(y_true, y_score,threshold = 0.5,prevalencia=None)
Métrica Valor --------------- -------- Accuracy 0.900585 MCC Normalizado 0.893571 Markedness 0.894841
Ejercicio 1.C
Usando los datos de test, calcula ahora las métricas para datos desbalaceados
- Jaccard
- F1-score
- Fowlkes-Mallows (FM)
- PR-AUC
La prevalencia a usar será la de los datos.
Crea la función jaccard,f1_score,fowlkes_mallows,pr_auc=get_metrics_datos_desbalaceados(y_true, y_score,threshold = 0.5,prevalencia=None)
Métrica Valor --------------- -------- Jaccard 0.853448 F1-score 0.92093 Fowlkes Mallows 0.92094 PR-AUC 0.921876
Ejercicio 2.A: Prevalencia
Porque no vamos a mostrar las siguientes métricas en una gráfica en función de la prevalencia
- Informedness Normalizado
- Balanced Accuracy
- 1-Prevalence threshold (PT)
- ROC-AUC
Ejercicio 2.B
Usando los datos de Test, muestra las siguientes métricas en función de la prevalencia [0,1].
- Accuracy
- Matthews correlation coefficient Normalizado (nMCC)
- Markedness
Además muestra una línea vertical con la prevalencia de los datos.

Ejercicio 2.C
Usando los datos de Test, muestra las siguientes métricas en función de la prevalencia [0,1].
- Jaccard
- F1-score
- Fowlkes-Mallows (FM)
- PR-AUC
Además muestra una línea vertical con la prevalencia de los datos.

¿Porqué no ha variado PR-AUC?
Ejercicio 2.D
Usando los datos de Test, muestra las siguientes métricas en función de la prevalencia [0,0.1].
- Jaccard
- F1-score
- Fowlkes-Mallows (FM)

clase/iabd/pia/2eval/tema08.metricas_derivadas.txt · Última modificación: 2025/03/05 11:45 por admin
Herramientas de la página
Excepto donde se indique lo contrario, el contenido de este wiki esta bajo la siguiente licencia: GNU Free Documentation License 1.3
