Tabla de Contenidos
2. Python
Para poder programar con Python vamos a usars el siguiente software:
- Visual Studio Code: El IDE
- Miniconda: Permite trabajar con los Jupyter Notebooks
- Extensiones de VS Code
- Diversas librerías de Python
Mas información:
- JupyterLab App:A desktop application for JupyterLab, based on Electron.

Instalación
Pasemos ahora a indicar todo lo que hay que instalar para poder trabajar en Python y los Jupyter notebooks.
Instalar Visual Studio Code
Ejecutar los siguiente comandos en las consola de Linux para instalar VS Code
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc cd /etc/yum.repos.d/ sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > vscode.repo' sudo dnf check-update sudo dnf install code
Instalar Miniconda
Descargar Miniconda desde https://docs.conda.io/en/latest/miniconda.html.
Ejecutar los siguiente comandos en las consola de Linux para instalar Anaconda
cd Descargas chmod +x Miniconda3-latest-Linux-x86_64.sh ./Miniconda3-latest-Linux-x86_64.sh
Instalar Extensiones de VS Code
Instalar las siguientes extensiones en VS Code
- Jupyter de Microsoft: Al instalar Anaconda despues de VS Code lo normal es que ya esté instalado.
Instalar paquetes de Python
Instalar antes que nada el paquete de Linux de Graphviz
sudo dnf install graphviz
Ahora vamos a instalar una serie de paquetes de Python en Anaconda. Se usa el comando conda
conda install numpy conda install pandas conda install matplotlib conda install seaborn conda install scikit-learn conda install tensorflow conda install keras conda install tabulate conda install pymysql conda install sqlalchemy conda install pydotplus conda install ipympl conda install opencv --channel conda-forge conda install pillow --channel anaconda conda install pandas_profiling --channel conda-forge
pandas_profiling no se encuentra en el canal (como un repositorio) oficial de Anaconda sino en el canal conda-forge. Por eso lo hemos indicado con --channel
Trabajar con Jupyter Notebooks
Para crear un nuevo Jupyter Notebook en VS Code deberemos pulsar las teclas CTRL+SHIFT+P y escribir "Jupyter: Create New Blank Notebook".
Dentro de un Jupyter Notebook podemos:
- "+ Codigo": Añadir un bloque de código
- "Ejecutar todo": Ejecuta todo desde el principio
- "Restart": Reinicia el entorno de ejecución y borra todas las variable pero no toca el código
Mas información:
El lenguaje Python
Un libro sobre Python lo puedes descargar aqui:Python para todos.Explorando la información con Python 3 y un sitio web sobre python es Python 3 para impacientes
Librerías
- Importar la librería
numpycon nombrenp
import numpy as np
- Importar una función
load_irisdesklearn.datasets
from sklearn.datasets import load_iris
Tipos
- Booleanos:
TrueyFalse - transformación de tipos
int()float()str()
- Redondear
round(valor,decimales)
Imprimir
- Imprimir
a=5 b="Hola" c=True d=6.7 print(a,b,c) print(d)
5 Hola True 6.7
- Para evitar el final de linea, se usa
end=""
a=5 b="Hola" c=True d=6.7 print(a,b,c,end="") print(d)
5 Hola True6.7
- Para quitar el separador, se usar
sep=""
a=5 b="Hola" c=True d=6.7 print(a,b,c,sep="") print(d)
5HolaTrue 6.7
- Para que el separador sea una coma, se usar
sep=","
a=5 b="Hola" c=True d=6.7 print(a,b,c,sep=",") print(d)
5,Hola,True 6.7
Ayuda
- Obtener información de una función, objeto ,etc. Solo hay que añadir la incógnita al final del nombre del método
abs?
Signature: abs(x, /) Docstring: Return the absolute value of the argument. Type: builtin_function_or_method
- Usado el método
help
help(abs)
Help on built-in function abs in module builtins:
abs(x, /)
Return the absolute value of the argument.
help otras veces de ?
- Las propiedades y métodos de una clase
from sklearn.preprocessing import StandardScaler standard_scaler = StandardScaler() dir(standard_scaler)
['__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', ...... 'set_output', 'set_params', 'transform', 'with_mean', 'with_std']
Operadores
- División entera
// - Resto de la división
% - Potencia
**
Estructuras de datos
- Arrays. Como Listas en Python.
a=[1,2,3] a[1]
2
- Tamaño de un Array
a=[1,2,3,3,1,2] len(a)
6
- Sumar los elementos de un array
a=[1,2,3,3,1,2] sum(a)
12
- Añadir un elemento a un array
a=[8,9,10] a.append(77) a
[8, 9, 10, 77]
- Concatenar arrays con el operador
+. Crea un nuevo array y sirve también para listas.
a=[1,2,3] b=[10,20,30] a+b
[1, 2, 3, 10, 20, 30]
- Usar
appendcon un array
a=[1,2,3] b=[10,20,30] a.append(b)
[1, 2, 3, [10, 20, 30]]
- Matrices. Como Arrays de Arrays en Python.
$$ \begin{pmatrix} 1 & 11\\ 2 & 22\\ 3 & 33 \end{pmatrix} $$
a=[ [1,11], [2,22], [3,33] ] a[2][1]
33
- Tuplas
a=(1,2,3) a[1]
2
- Diccionarios
a= {
"nombre":"Juan",
"edad": 37
}
a['edad']
37
- Claves diccionarios. Para obtener las claves de un diccionario se usa el método
keys()
a= {
"nombre":"Juan",
"edad": 37
}
for key in a.keys():
print(key)
nombre edad
Imprimir matrices
Para imprimir datos en forma tabular, es necesario tenerlas en una matriz. Y para imprimir usaremos la librería tabulate
from tabulate import tabulate datos=[ [5,0.7,0.765], [10,1.45,0.84], [20,2.678,0.978], [60,11.396,0.9973] ] print(tabulate(datos, headers=["Épocas", "Tiempo (s)", "Resultado"]))
Épocas Tiempo (s) Resultado
-------- ------------ -----------
5 0.7 0.765
10 1.45 0.84
20 2.678 0.978
60 11.396 0.9973
También podemos añadir una primera columna que sean también como "cabeceras". El siguiente anterior ejemplo se podría modificar de forma que en el array a solo estén los datos de tiempo y resultado y no las épocas ya que son como "cabeceras".
from tabulate import tabulate datos=[ [0.7,0.765], [1.45,0.84], [2.678,0.978], [11.396,0.9973] ] epocas=[5,10,20,60] print(tabulate(datos, headers=["Épocas", "Tiempo (s)", "Resultado"],showindex=epocas))
Épocas Tiempo (s) Resultado
-------- ------------ -----------
5 0.7 0.765
10 1.45 0.84
20 2.678 0.978
60 11.396 0.9973
Estructuras de control
- Condicional
a=1
if a==1:
b=4
else:
b=5
print(b)
4
a=2
if a==1:
b=4
elif a==2:
b=-1
else:
b=5
print(b)
-1
- Bucles
a=[0,1,2,3]
for i in a:
print(i)
0 1 2 3
for i in range(0,4):
print(i)
0 1 2 3
- enumerate: Permite recorres un array pero obteniendo tanto el valor como el índice dentro del array
precios=[45,234,6.99,7]
for index_precio,precio in enumerate(precios):
print(index_precio,precio)
0 45 1 234 2 6.99 3 7
Funciones
- Función que retorna un valor
def sumar(a,b):
return a+b
resultado=sumar(3,4)
print(resultado)
7
- Función que retorna 2 valores y se almacenan en dos variables
def sumar_y_multiplicar(a,b):
return a+b,a*b
a,b=sumar_y_multiplicar(3,4)
print(a)
print(b)
7 12
- Función que retorna 2 valores y se almacenan en una única variable
def sumar_y_multiplicar(a,b):
return a+b,a*b
resultado=sumar_y_multiplicar(3,4)
print(resultado)
print(resultado[0])
print(resultado[1])
(7, 12) 7 12
- Llamar a funciones por nombre de los parámetros
def dividir(dividendo,divisor):
return dividendo/divisor
print(dividir(10,2))
print(dividir(dividendo=10,divisor=2))
print(dividir(divisor=2,dividendo=10))
print(dividir(10,divisor=2))
5.0 5.0 5.0 5.0
- Parámetros opcionales
def dividir(dividendo,divisor=2):
return dividendo/divisor
print(dividir(10,2))
print(dividir(10))
print(dividir(10,4))
print(dividir(dividendo=10))
5.0 5.0 2.5 5.0
Clases
Para crear clases en python:
class: Se crear la claseself: Para referirse a propiedades y métodos del propio objeto, se pasa siempre como primer argumento en todos los métodos.__init__: El nombre del constructor
- Vamos a crear la clase rectángulo
class Rectangulo:
def __init__(self, longitud, ancho):
self.longitud = longitud
self.ancho = ancho
def calcular_area(self):
return self.longitud * self.ancho
def calcular_perimetro(self):
return 2 * (self.longitud + self.ancho)
- Ahora vamos a usar la clase que hemos creado
mi_rectangulo = Rectangulo(5, 10)
print("Longitud:", mi_rectangulo.longitud)
print("Ancho:", mi_rectangulo.ancho)
print("Área:", mi_rectangulo.calcular_area())
print("Perímetro:", mi_rectangulo.calcular_perimetro())
Longitud: 5 Ancho: 10 Área: 50 Perímetro: 30
Medición de rendimiento
timeit
IPython es como la forma genérica de los Jupyter Notebooks. Y tiene una serie de órdenes que podemos usar directamente. La orden %timeit permite saber el tiempo que ha tardado una orden en ejecutarse.
time = %timeit -n1 -r1 -o sum(range(10000000))Lo que hace es calcula el tiempo de ejecutar la orden
sum(range(1000000000)) y almacena cuanto ha tardado en time
Y para imprimirlo, se usa:
print(round(time.average,2),"seg")
0.21 seg
Sin embargo el problema de usar %timeit es que lo que ejecutas no puede devolver un resultado. Es decir que no podríamos saber el resultado de la suma.
perf_counter
Para solucionar el problema anterior podemos simplemente medir nosotros el tiempo que tarda un método en ejecutarse con la función perf_counter.
from time import perf_counter t = perf_counter() resultado=sum(range(10000000)) t=perf_counter()-t print(resultado) print(round(t,2),"seg")
49999995000000 0.21 seg
El resultado se muestra en segundos
Mas información:
Poetry
A veces no quieremos usar conda sino tener una carpeta con todo lo que necesita el proyecto, al estilo de NodeJS. En ese caso podemos usar una herramienta llamada Poetry
- Instalar poetry
pip install --user poetry
- Comprobar que tenemos poetry instalado
poetry --version
- Para decir que las librerías se instalen en nuestra propia carpeta del proyecto.
poetry config virtualenvs.in-project true
- Para tener un proyecto con python y todas sus dependencias en la misma carpeta haremos lo siguiente:
poetry init poetry add libclang = "<12.0.0" numpy pandas matplotlib seaborn scikit-learn tensorflow tabulate PyMySQL SQLAlchemy ipympl keras-tuner tensorflow-addons statsmodels poetry install
poetry add se produce el error:
[org.freedesktop.DBus.Error.UnknownObject] ("No such object path '/org/freedesktop/secrets/aliases/default'",)
deberemos crear la siguiente variable de entorno:
export PYTHON_KEYRING_BACKEND=keyring.backends.null.Keyring
Para ejecutar el código hay 2 formas:
- Desde la línea de comandos:
poetry run python my_script.py
- Desde VS Code seleccionar en los entornos de ejecución la carpeta
.venvdel propio proyecto:
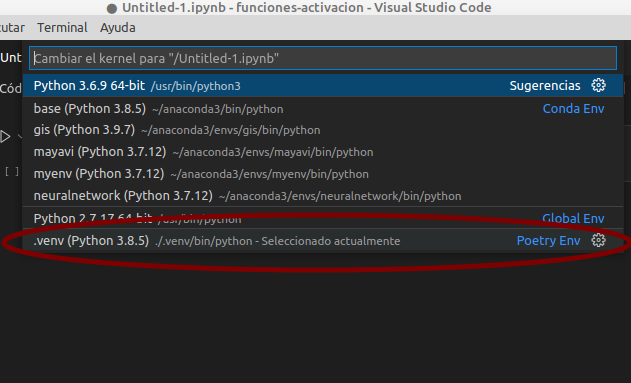
- Si queremos usar el entorno de poetry pero no está en nuestra carpeta se puede indicar a VS Code cual es el ejecutable de python que debe usar siempre para ello hay que crear en la carpeta de nuestro proyecto el fichero
$HOME/.config/Code/User/settings.json
{
"python.defaultInterpreterPath": "/home/logongas/python_default_env/.venv/bin/python",
}
Ejercicios
Ejercicio 1: Instalación
Instala todo lo indicado en el apartado "Instalación" de este tema
Ejercicio 2: Librerías
- Importa la librería llamada
numpycon el nombre denp - Importa la librería llamada
pandascon el nombre depd - Importa la librería llamada
matplotlib.pyplotcon el nombre deplt - Importa la librería llamada
seaborncon el nombre desns - Importa una función
load_breast_cancerdesdesklearn.datasets
Una vez importadas esas librerías ejecuta el siguiente código, el cual mostrará una gráfica.
df=pd.DataFrame({
'Perímetro medio':load_breast_cancer().data[:,2],
'¿Benigno?':load_breast_cancer().target,
})
figure=plt.figure()
axes = figure.add_subplot()
sns.scatterplot(data=df,x="Perímetro medio",y="¿Benigno?")
Ejercicio 3: Tipos
- Crea 2 variables booleanas una con el valor verdadero y otra con el valor falso.
- Crea una variable de tipo
Stringcon un número y la transformas en unint. - Crea una variable de tipo
Stringcon un número y la transformas en unfloat. - Crea una variable de tipo
inty la transformas en unfloat. - Crea una variable de tipo
inty la transformas en unString. - Crea una variable de tipo
floaty la transformas en unString. - Crea una variable de tipo
floaty la transformas en unint. ¿La función redondea o trunca?
Ejercicio 4.A: Ayuda
- Muestra la ayuda de la función
load_breast_cancermediante?
Ejercicio 4.B: Ayuda
- Muestra la ayuda de la función
load_breast_cancermediantehelp
Ejercicio 4.C: Ayuda
- Muestra los campos del objeto
datos, sabien que el objeto datos se obtiene así:
datos=load_breast_cancer()
Ejercicio 5: Operadores
- Haz la división con decimales de 5/3
- Haz la división entera de 5/3
- Calcula $2^{16}$
Ejercicio 6: Arrays
- Crea una array con los siguiente números primos e imprime el cuarto número: 2, 3, 5, 7, 11, 13, 17, 19, 23, 29
- Calcula la longitud del anterior array
- Calcula la suma de los elementos del anterior array
- Añade al array el elemento 97
- Crea una tupla con los siguiente números primos e imprime el cuarto número: 2, 3, 5, 7, 11, 13, 17, 19, 23, 29
- Añade a la tupla el elemento 97. ¿Porqué no te deja?.
- Crea una array que sea la unión de los elementos de los siguientes dos arrays
1,2,3,4y10,20,30,40. Deberás usar un buclefor. - Añade al array
1,2,3,4el siguiente array10,20,30,40, pero como si fuera un único elemento usando una sola vezappend. ¿Ves la diferencia con el ejercicio anterior?
Ejercicio 7: Print y arrays
Dado el array:
a=[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
- Imprime todos sus números cada un en una línea distinta
- Imprime todos sus números en una única línea y separados por punto y coma
- Imprime todos sus números en una única línea y separados por un espacio
- Imprime todos sus números de forma que se impriman 2 por línea y separados por una coma
- Imprime todos sus números de forma que se impriman 3 por línea y separados por un espacio
Ejercicio 8: Matrices
- Crea la siguiente matriz:
$$ \begin{pmatrix} 1 & 0 & 0 & 0\\ 0 & 1 & 7 & 0\\ 0 & 0 & 1 & 0\\ 0 & 0 & 0 & 1\\ \end{pmatrix} $$
- Obtén el elemento de la fila 2º y la columna 3º. Es el valor del 7.
- Crea un nuevo array con los elementos de la 3º Fila de la matriz
- Crea un nuevo array con los elementos de la 2º Columna de la matriz
- Imprime la matriz y haz que las cabeceras de cada columna sean A, B , C y D
Ejercicio 9: Diccionarios
- Crea una variable llamada
clienteque sea un diccionario con la información de este cliente
nombre: Juan
apellidos: Pérez García
teléfono
movil: 654789658
fijo: 963789654
dirección:
tipo via: calle
numero: 45
puerta: 7
numero facturas:
compras: 234/2020, 345/2021, 675/2021, 561/2022
ventas: 456/2020, 564/2021, 768/2021, 345/2022
- Del anterior diccionario muestra la siguiente información:
- nombre
- El teléfono móvil
- El tipo de vía
- El número de la 3º factura que vendió
- La cantidad de compras que ha hecho.
- Imprime el nombre de las claves del "primer nivel"
Ejercicio 10: Estructuras de control
Usando la variable cliente del ejercicio anterior, haz lo siguiente:
- Muestra el texto "Cliente Importante" si el número de compras es mayor que 5 o sino muestra "Cliente Normal"
- Muestra el texto "Cliente Importante" si el número de compras es mayor que 5 , si el número de compras es entre 2 y 5 muestra "Cliente Normal" , sino muestra "Cliente poco importante"
- Haz que se muestre por pantalla los números del 0 al 999
- Haz que se muestre por pantalla los números del 1 al 1000
- Crea un array con los números primos hasta el 100, que son
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97- Muestra cada número por pantalla.
- Haz que se muestren por pantalla el número junto con el orden que ocupan. Por ejemplo
4º -> 7,6º -> 13 - Modifica el ejercicio anterior de forma que si es el primer número primo del array, se muestre
Primero -> 2y si es el último número primo del array , se muestreUltimo -> 97
Ejercicio 11: Funciones
- Haz una función llamada "importe_final que dado el precio de un producto y el porcentaje de descuento , nos diga el importe del producto. Usa la función con los valores de 120€ y un 10% e imprime el resultado. Vuelve a llamar ahora a la función pero cambiando el orden de los argumentos y usando el nombre de los parámetros en la llamada
- Modifica la función para que retorne tanto el importe como la cantidad que se ha descontado del precio. Usa la función con los valores de 120€ y un 10% e imprime el resultado.
- Modifica la función para que por defecto el descuento sea un 10% y no sea necesario pasar ese valor. Usa la función con el valor de 120€ e imprime el resultado.
Ejercicio 12
Vamos a volver al ejercicio de redes neuronales del tema 1 del tipo de flor .
Modifica el siguiente programa:
model=Sequential() model.add(Dense(6, activation='relu',input_dim=2)) model.add(Dense(12, activation='relu')) model.add(Dense(6, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='mean_squared_error') model.fit(x, y,epochs=40)
Para que en vez de poner tantas líneas como capas hay , se haga con un array. Es decir que dado el array capas=[6,12,6,1] se cree la red anterior pero si cambiamos los datos del array que se cree la red correspondiente.
Ejercicio 13
Modifica el ejercicio anterior de forma que el código esté en una función llamada compile_fit que haga lo mismo y retorne el objeto model.
Prueba a llamar a la función con los siguientes datos
capas_red1=[6,12,6,1] model1=compile_fit(capas_red1,x,y) capas_red2=[8,16,8,1] model2=compile_fit(capas_red2,x,y)
Además, encapsula la obtención de los datos en la función get_datos
x,y=get_datos()
Ejercicio 14
Siguiendo con el ejercicio anterior, haz un programa que muestre lo siguiente
Red Result 1 Result 2 ------ ---------- ---------- 1 0.06094426 0.9634158 2 0.06094426 0.9634158 ... 5 0.06094426 0.9634158
Pero los números con decimales que se muestran son el resultado de llamar a la red neuronal con los valores (4.9, 1.4) y (6.3, 4.9). Y cada red va a tener las siguientes capas con las neuronas:
| Red | Nº Neuronas en cada capa |
|---|---|
| 1º | 2, 4, 1 |
| 2º | 4, 8, 8, 2, 1 |
| 3º | 8, 12, ,24, 12, 1 |
| 4º | 8, 16, 8, 1 |
| 5º | 16, 32, 1 |
Para hacer eso deberás crear un array en la que cada elemento será otro array con las neuronas de cada capa. Ejemplo:
redes=[ [2, 4 , 1] , [4, 8, 8, 2, 1] ]
- Recorre el array y en cada vuelta
- Obtén las neuronas de cada capa
- Llama al método
compile_fit - Obtén los resultados de predecir con los valores (4.9, 1.4) y (6.3, 4.9).
- Añade los resultados a una matriz de resultados
- Imprime la matriz de resultados
Ejercicio 15
Modifica el ejercicio anterior para que el método compile_fit retorna además del objeto model , el tiempo en segundos (con 2 decimales) que ha tardado en ejecutarse el método fit
Y que en la tabla se muestre también el tiempo
Red Result 1 Result 2 Tiempo (s) ------ ---------- ---------- ------------ 1 0.06094426 0.9634158 0.4 2 0.06094426 0.9634158 1.56 ... 5 0.06094426 0.9634158 12.71
Ejercicio 16
Modifica el ejercicio anterior pero ahora modifica en el array de cada red para que la columna Red sea el nombre de la red para que podamos saber cual es cada una. El nombre será las neuronas de cada capa
Red Result 1 Result 2 Tiempo (s) ---------- ---------- ---------- ------------ 2,4,1 0.06094426 0.9634158 0.4 4,8,8,2,1 0.06094426 0.9634158 1.56 ... 16,32,1 0.06094426 0.9634158 12.71
Ejercicio 17
Modifica el ejercicio anterior pero ahora incluye en el array de cada red un nuevo campo con el número de épocas con las que se ha entrenado.
Por ello , deberás incluir un nuevo valor para cada red que será el número de épocas a entrenar.
Ejemplo:
redes=[ [[2, 4 , 1], 30] , [[4, 8, 8, 2, 1], 34] ]
El último elemento de cada array en el número de épocas que se va a entrenar la red.
Red Épocas Result 1 Result 2 Tiempo (s) ---------- -------- ---------- ------------ 2,4,1 30 0.06094426 0.9634158 0.4 4,8,8,2,1 34 0.06094426 0.9634158 1.56 ... 16,32,1 20 0.06094426 0.9634158 12.71
Ejercicio 18
Modifica la función compile_fit añadiendo un nuevo parámetro que se a el número de neuronas de entrada. Es decir, el número de valores de la "x".
Ejercicio 19
Repite el ejercicio anterior pero ahora con la red neuronal del cáncer de mama y las siguientes capas de la red:
| Nº Neuronas en cada capa | Épocas |
|---|---|
| 4, 8, 4, 2, 1 | 20 |
| 4, 8, 4, 2, 1 | 40 |
| 8, 16, 8, 4, 1 | 20 |
| 8, 16, 8, 4, 1 | 40 |
| 16, 32, 16, 8, 1 | 20 |
| 16, 32, 16, 8, 1 | 40 |
| 32, 64, 32, 8, 1 | 20 |
| 32, 64, 32, 8, 1 | 40 |
| 64, 128, 64, 8, 1 | 20 |
| 64, 128, 64, 8, 1 | 40 |
Ejercicio 20
Crea una clase llamada CuentaBancaria.
La clase debe tener los siguientes atributos:
titular: el titular de la cuenta.saldo: el saldo actual de la cuenta.
La clase debe tener los siguientes métodos:
__init__: el método de inicialización que toma el titular como parámetro e inicializa el saldo en 0.depositar: un método que toma una cantidad como parámetro y la suma al saldo actual.retirar: un método que toma una cantidad como parámetro y la resta del saldo actual, pero verifica que haya suficiente saldo antes de realizar la operación.obtener_saldo: un método que devuelve el saldo actual de la cuenta.
Usa la clase de forma que
- Se cree un objeto
- Se depositen 100€
- Se retiren 75€.
- Imprimas el titular y el saldo.