7.c Código
Durante el tema hemos visto los gráficos que explican el descenso de gradiente. Veamos ahora como se pueden hacer dichos gráficos en Python.
La función que coste que hemos usado es la siguiente
$$ loss(w_0,w_1)=3(1-w_0)^2e^{-w_0^2-(w_1+1)^2}-10(\frac{w_0}{5}-w_0^3-w_1^5)e^{-w_0^2-w_1^2}-\frac{1}{3}e^{-(w_0+1)^2-w_1^2} $$
cuya gráfica es la siguiente:
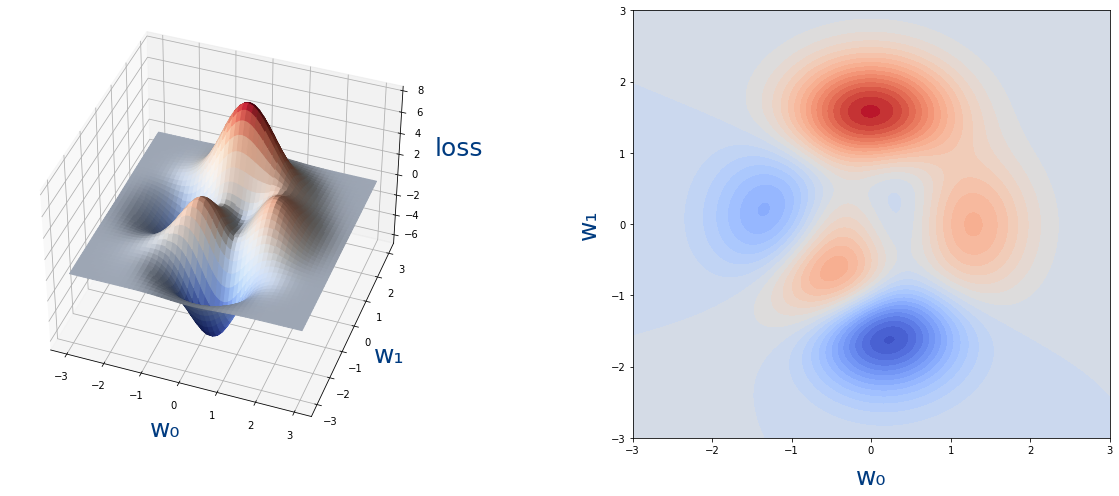
En python la función $loss(w_0,w_1)$ con NumPy sería así:
def loss(w_0,w_1):
return 3*(1 - w_0)**2 * np.exp(-w_0**2 - (w_1 + 1)**2) - 10*(w_0/5 - w_0**3 - w_1**5)*np.exp(-w_0**2 - w_1**2) - 1./3*np.exp(-(w_0 + 1)**2 - w_1**2)
Y el algoritmo que calcula cada uno de los $w_0,w_1$ del descenso de gradiente es el siguiente:
def get_puntos_descenso_gradiente(epochs,learning_rate,w_0_original,w_1_original):
w_0=w_0_original
w_1=w_1_original
puntos_descenso_gradiente=np.array([[w_0,w_1]])
for epoch in range(epochs):
h=0.00001
gradiente_w_0=(loss(w_0+h,w_1)-loss(w_0,w_1))/h
gradiente_w_1=(loss(w_0,w_1+h)-loss(w_0,w_1))/h
#Nuevos valores de los pesos
w_0=w_0-learning_rate*gradiente_w_0
w_1=w_1-learning_rate*gradiente_w_1
puntos_descenso_gradiente=np.append(puntos_descenso_gradiente,[[w_0,w_1]], axis=0)
return puntos_descenso_gradiente
Si ejecutamos lo siguiente:
get_puntos_descenso_gradiente(5,0.03,-0.35,-0.67)
El resultado es:
array([[-0.35 , -0.67 ],
[-0.26931594, -0.72470447],
[-0.13292324, -0.838827 ],
[ 0.0654496 , -1.06459902],
[ 0.24087009, -1.40749396],
[ 0.2657862 , -1.59573582]])
Que son cada uno de los valores de $w_0,w_1$ que empiezan en -0.35, -0.67 y acaban en 0.2657862, -1.59573582$
Pasamos ahora a mostrar los valores dentro de la gráfica de la función, para ello hemos creado 2 funciones:
plot_loss_function: Que dibuja la superficie con todos los coloresplot_descenso_gradiente: Dibuja los puntos por donde va pasando el algoritmo del descenso de gradiente
def plot_loss_function(axes,fontsize=25,title=""):
rango_w_0=np.linspace(-3,3,100)
rango_w_1=np.linspace(-3,3,100)
rango_w_0,rango_w_1=np.meshgrid(rango_w_0,rango_w_1)
loss=loss_function(rango_w_0,rango_w_1)
axes.contourf(rango_w_0,rango_w_1,loss,30,cmap="coolwarm")
axes.set_xlabel('w₀',fontsize=fontsize,color="#003B80")
axes.set_ylabel('w₁',fontsize=fontsize,color="#003B80")
axes.set_title(title)
def plot_descenso_gradiente(axes,puntos_descenso_gradiente):
axes.scatter(puntos_descenso_gradiente[1:-1,0],puntos_descenso_gradiente[1:-1,1],13,color="yellow")
axes.plot(puntos_descenso_gradiente[:,0],puntos_descenso_gradiente[:,1],color="yellow")
axes.plot(puntos_descenso_gradiente[0,0],puntos_descenso_gradiente[0,1],"*",markersize=12,color="red")
axes.plot(puntos_descenso_gradiente[-1,0],puntos_descenso_gradiente[-1,1],"*",markersize=12,color="blue")
Si ejecutamos el código:
figure=plt.figure(figsize=(16,15)) axes = figure.add_subplot() plot_loss_function(axes) plot_descenso_gradiente(axes,get_puntos_descenso_gradiente(5,0.03,-0.35,-0.67))
Vemos la siguiente gráfica donde se muestran los puntos que hemos obtenido de la función get_puntos_descenso_gradiente
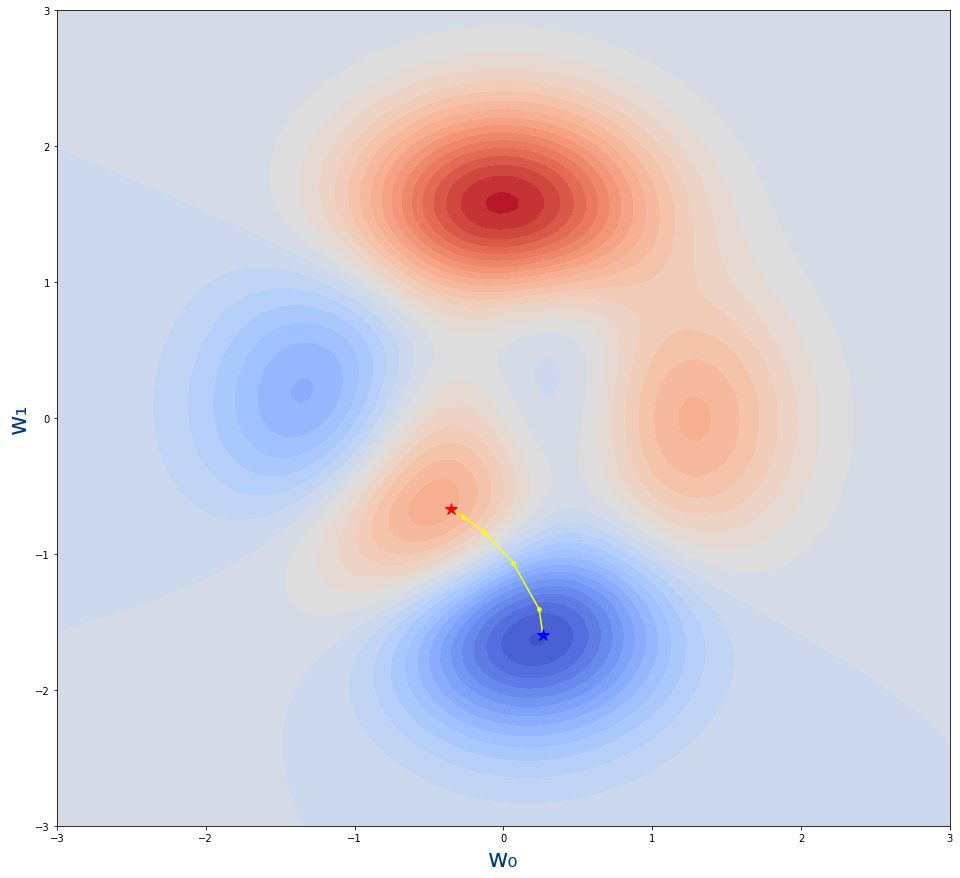
- La estrella roja es desde donde empieza el algoritmo.Es decir, el valor inicial de los parámetros $w_0,w_1$
- La estrella azul es donde acaba el algoritmo.Es decir, el valor tras el entrenamiento de los parámetros $w_0,w_1$
- Los puntos amarillo son los pasos por lo que se va moviendo el algoritmo. Cada uno de los valores intermedios de los parámetros durante el entrenamiento.